
Docker Desktop inclut optionnellement un cluster Kubernetes local. Dans ce long article, je décris une mise en pratique de comment concrètement on peut tester une application composée de plusieurs services, et déboguer ceux-ci au besoin, dans le cluster Kubernetes local de Docker Desktop, avec des exemples réalistes, à savoir des dépendances d’infrastructure à SQL Server, à Azure Service Bus et à Azure Storage (Blob containers).
Je n’utilise pas l’intégration du projet C# à Docker via Visual Studio, qui génère un Dockerfile et a donc un impact sur le contenu de la solution. La méthode que je décris ici est complètement indépendante de comment on choisit de créer ses Dockerfiles et de leur emplacement dans ou hors de la solution. Je voulais une expérience en local qui soit la moins intrusive sur la solution dans Visual Studio (et sur ce qu’on persiste dans son dépôt Git).
Cette méthode peut évidemmment fonctionner pour un seul service, mais elle a peu d’intérêt dans ce cas. En revanche, dans une solution (ou plusieurs) qui composent plusieurs services, cela prend tout son sens. En phase de développement, on doit tester en permanence, plusieurs fois par jour, les services développés. Soit de manière très ciblée, dans un service, auquel cas on revient sur l’approche d’un seul exécutable où il y a sans doute peu de sens à se lancer dans la conteneurisation en local. Mais plus souvent probablement, on souhaite tester l’application composée de plusieurs services. La tendance de la dernière décennie est aux microservices. Terme souvent très discutable dans son application en réalité, il n’en est pas moins qu’une approche classique est d’avoir une solution qui regroupe tous ces soit-disant microservices, pour un aspect pratique pour le développement certes, mais un peu contradictoire à mon sens, puisque toujours par facilité, on aura tendance à ensuite déployer tous ces services en un bloc cohérent. Si au contraire, on choisit l’approche plus « puriste » de découper ces services au sein de plusieurs solutions indépendantes (qu’on déploiera dans ce cas typiquement de manière réellement indépendante), l’expérience de développement au quotidien est encore moins bonne avec l’approche qu’on va appeler traditionnelle, c’est-à-dire lancer tous ces services en mode « Debug » depuis Visual Studio. On se retrouve avec un enchevêtrement de consoles dont l’organisation n’est pas toujours facile. Bien que Windows Terminal ait beaucoup amélioré cette expérience (on peut regrouper ces consoles sous forme d’onglets), l’expérience n’est quand même pas optimale. Ne serait-ce que pour suivre ce qu’il se passe dans la sortie console de chaque service, mais ce n’est qu’un aspect.
Finalement, la technique que je décris dans cet article se focalise sur cet aspect d’une application composée de plusieurs services (et plus il y en a, plus il y d’intérêt à avoir cet outil à sa disposition). Le fait qu’il s’agit de microservices n’a pas d’incidence.
Pourquoi déboguer dans des containers sur un poste Windows ?
J’ai déjà esquissé quelques réponses plus haut. C’est avant tout intéressant si on est amené à travailler, par choix ou non, sur une application composée de plusieurs services. Je ne soutiens pas qu’il faille toujours lancer l’application en local dans des containers.
On peut même faire un mix des deux approches: lancer en local (depuis Visual Studio) le service qu’on souhaite déboguer, et laisser les autres services requis tourner dans le cluster Kubernetes. Il faut par contre prendre soin désactiver l’instance du service dans Kubernetes si on le lance en local pour éviter des effets de bord indésirables. Le service local peut toujours communiquer avec les autres services dans le cluster Kubernetes Local, par exemple via le Service Bus ou des appels HTTP.
Pour conclure, il ne s’agit pas de dire qu’il faut déboguer depuis un cluster Kubernetes local mais plutôt d’être en capacité d’utiliser cet outil supplémentaire si cela apporte quelque chose de plus dans notre travail au quotidien.
Pourquoi Kubernetes au lieu de Docker Compose ?
Premièrement, je préfère me limiter à (bien) connaître Kubernetes, qui est le standard de-facto pour l’orchestration de containers en production, plutôt que devoir travailler avec plusieurs technologies dont une que je n’utiliserai pas en dehors de tests en local. Cela fait moins de choses à apprendre et à suivre, et donc moins de charge cognitive. C’est très subjectif, je comprends qu’on puisse préférer « toucher » à tout.
Deuxièmement, si l’application est au final déployée sur Kubernetes (ou dans Azure Container Apps qui masque la présence d’un cluster Kubernetes), je trouve qu’il est plus cohérent d’utiliser Kubernetes en local même si Docker Compose pourrait être utilisé.
Pourquoi Kubernetes avec Docker Desktop ?
Dans ma démarche personnelle, j’ai commencé par utiliser Minikube. Cela fonctionne bien, mais l’expérience est au final moins bonne qu’avec Docker Desktop (avec le backend WSL2)
Docker Desktop a lui aussi quelques inconvénients:
-
Le démarrage de Kubernetes dans Docker Desktop semble un peu moins fiable (il est en revanche plus rapide que Minikube quand ça fonctionne bien): il m’est arrivé de devoir arrêter et relancer Docker Desktop parce que le cluster Kubernetes ne démarrait pas correctement. Plus ponctuellement encore, il m’a fallu redémarrer la machine pour que tout rentre dans l’ordre. Ca reste cependant suffisamment rare et rapide à résorber pour que ce ne soit pas trop gênant.
-
Les volumes persistants sont moins bien gérés: il faut des manifestes spécifiques pour avoir des volumes réellement persistants entre deux démarrages de Docker Desktop. Ça semble être lié au fonctionnement de Docker Desktop avec WSL2. Je détaillerai ici comment je m’y suis pris mais je n’entrerai pas dans le détail car ce n’est pas l’objet de l’article. De toutes façons, pour une bonne expérience de déboguage en local, on se retrouve à créer des manifestes spécifiques, différents de ceux qu’on utiliserait pour un vrai déploiement de l’application, donc ce n’est pas si gênant.
Tout comme Minikube, Docker Desktop dépend de WSL2. Ce dernier peut être mis à jour par Windows un peu n’importe quand, et quand ça arrive, WSL est arrêté sans prévenir, ce qui fait planter Docker Desktop avec le message « Docker Desktop – WSL distro terminated abruptly » (j’ai identifié Windows Update comme étant la cause grâce aux journaux d’événements système). Le redémarrage de Docker Desktop fonctionne bien après ce type d’événement, mais il est bon d’avoir en tête que ce type de désagrément arrive avec cette solution (sauf à configurer Windows Update pour ne pas appliquer de mise à jour pendant la plage horaire qui vous intéresse).
Comment ça fonctionne ?
J’utilise indifféremment le terme méthode, technique, outil, pour décrire comment mettre en oeuvre une expérience de développement adaptée à une application composée de plusieurs services .NET, sur un ordinateur Windows. Comme il s’agit simplement de techniques et d’outils, c’est en fait transposable à d’autres situations. A contrario, ce n’est pas une recette entièrement connue à l’avance, il n’y a pas un script tout fait réutilisable sur n’importe quel projet, il faudra faire vos propres scripts. L’expérience probablement la plus proche, toute intégrée, sans avoir à trop réfléchir soit-même à sa méthode de travail est probablement le nouveau .NET Aspire. Comme dit précédemment, l’avantage de la technique décrite ici est qu’elle est en fait plus simple (à mon avis), et indépendante des choix adoptés au sein de la solution Visual Studio.
Pour commencer, il faut avoir un ordinateur suffisamment puissant, mais rien d’exceptionnel non plus pour du développement dans de bonne conditions (un bon ordinateur portable fait parfaitement l’affaire). La charge supplémentaire en terme de mémoire vive en particulier n’est pas anodine. 32 Go de RAM me paraît être l’idéal actuellement (16 est probablement suffisant mais peut-être un peu juste). Il y a un coût « de base » avec Docker Desktop et Kubernetes, ensuite tout dépend des ressources déployées dans le cluster bien évidemment.
L’idée générale est:
- Pour Kubernetes en local: utiliser la fonctionnalité Kubernetes offerte par Docker Desktop.
- Développer et utiliser un ensemble de scripts assez simples (quelques exemples à adapter sont dans cet article) :
-
Un premier qui va créer ou transformer des Dockerfiles, et qui sert à alimenter le cache d’images locales de Docker Desktop avec les services à lancer dans Kubernetes. Si les Dockerfiles contiennent des instructions inutiles pour le run local, tels que les tests unitaires et sonar scanner, ce script les retire pour conserver le minimum requis pour compiler et lancer l’application. C’est le plus simple à gérer (édition de fichiers, exécution des commandes
docker buildadéquates). -
Un deuxième qui va générer les manifestes requis par Kubernetes, spécifiques à chaque service, en fonction notamment des fichiers de configuration propres à une solution .NET (« appsettings.json », « appsettings.Development.json », user secrets, variables d’environnement éventuelles).
Cette partie notamment est sans doute celle qui requiert le plus de connaissances techniques sur le projet (ce qui devrait être un acquis si on travaille dessus) et sur Kubernetes. Il n’est pas spécialement indispensable de bien connaître Kubernetes, c’est toujours un peu la même chose si on part de quelques exemples illustratifs.
-
Un dernier script qui sert au déploiement dans Kubernetes, et qui soit capable de redémarrer les services si on a mis à jour les images Docker, ou d’arrêter tous les services pour économiser des ressources quand elles ne sont plus utiles (on peut aussi arrêter ou démarrer facilement Docker Desktop mais l’opération est plus longue). Le script en lui-même est très simple, mais il s’appuie sur OpenTofu.
-
- Si on souhaite déboguer un service, on pourra très facilement attacher le débogueur de Visual Studio à un container (c’est nativement supporté par les versions récentes de Visual Studio).
- Déployer d’autres ressources plus ou moins open source mais en tout cas gratuites qu’on pourra interfacer, notamment un ou plusieurs outils de monitoring pour avoir une vue unifiée des logs (le plus important), mais également des traces distribuées. J’utilise personnellement Signoz avec satisfaction. Entrent également dans cette catégorie les émulateurs type Azure Service Bus Emulator et Azurite si le projet dépend des services Azure correspondants.
- Utiliser la fonctionnalité port-forward de Kubernetes, qui permet de communiquer avec un service du cluster Kubernetes via l’interface « localhost » de sa machine. Si possible avec client graphique qui sera très pratique car c’est quelque chose qu’on utilisera très souvent. J’utilise personnellement Kube Forwarder qui fait parfaitement le job.
- Si le projet dépend d’un serveur de base de données (par exemple SQL Server ou Postgresql) ou même d’autres types de dépendances comparables, il est possible de réutiliser l’instance de la machine et la rendre accessible aux containers. C’est ce que je fais avec SQL Server que je préfère avoir directement en local et pas dans un container, même si c’est techniquement possible. L’avantage est que je peux continuer à lancer certains projets en local, qui dépendent de SQL Server, sans dépendre de Docker Desktop si je le souhaite (et sans avoir à héberger plusieurs serveurs, très consommateurs de mémoire).
- On pourra aussi utiliser d’autres outils de l’écosystème Kubernetes, comme K9s pour suivre d’un coup d’oeil le statut des containers.
Ayant pratiqué cette méthode depuis un certain temps sur un projet où je la trouve particulièrement utile, j’y ai trouvé plusieurs avantages que je n’avais pas anticipé: j’ai généralement peu besoin de m’attacher à un service en mode déboguage, je m’intéresse davantage à suivre facilement ses traces et logs. Quand on lance un service en mode debug en local, on a tendance lancer, et arrêter le service de nombreuses fois. En déployant le service dans un container, celui-ci tourne en permanence, on peut s’y attacher ponctuellement et se détacher sans que cela affecte son cycle de vie. Je sais que tout ce cela est possible en local, mais c’est moins pratique car ce n’est pas l’approche traditionnelle.
Mise en pratique
Kubernetes avec Docker Desktop
Cette partie est la plus simple, il suffit d’installer Docker Desktop avec l’intégration à WSL2.
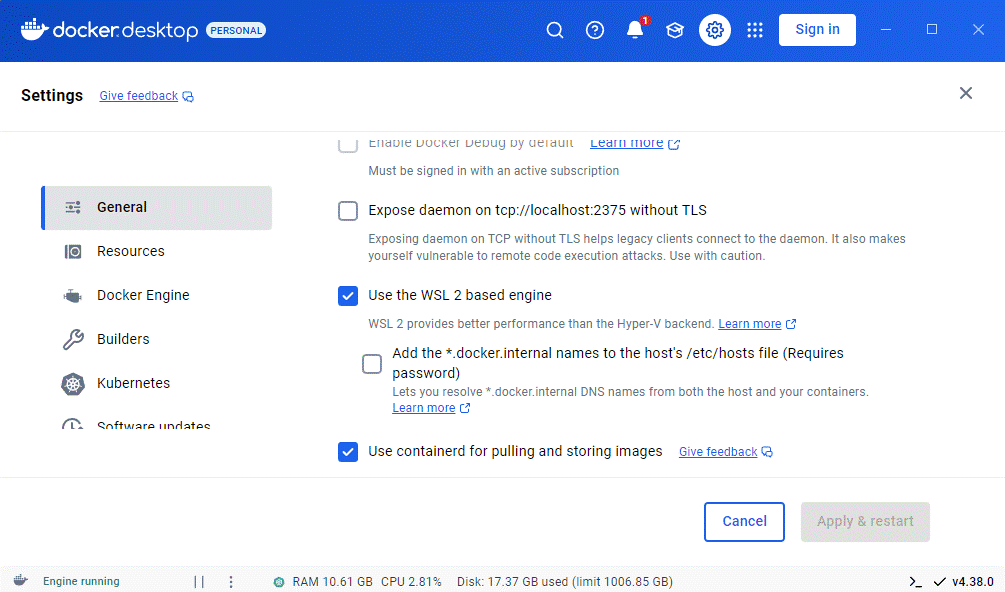
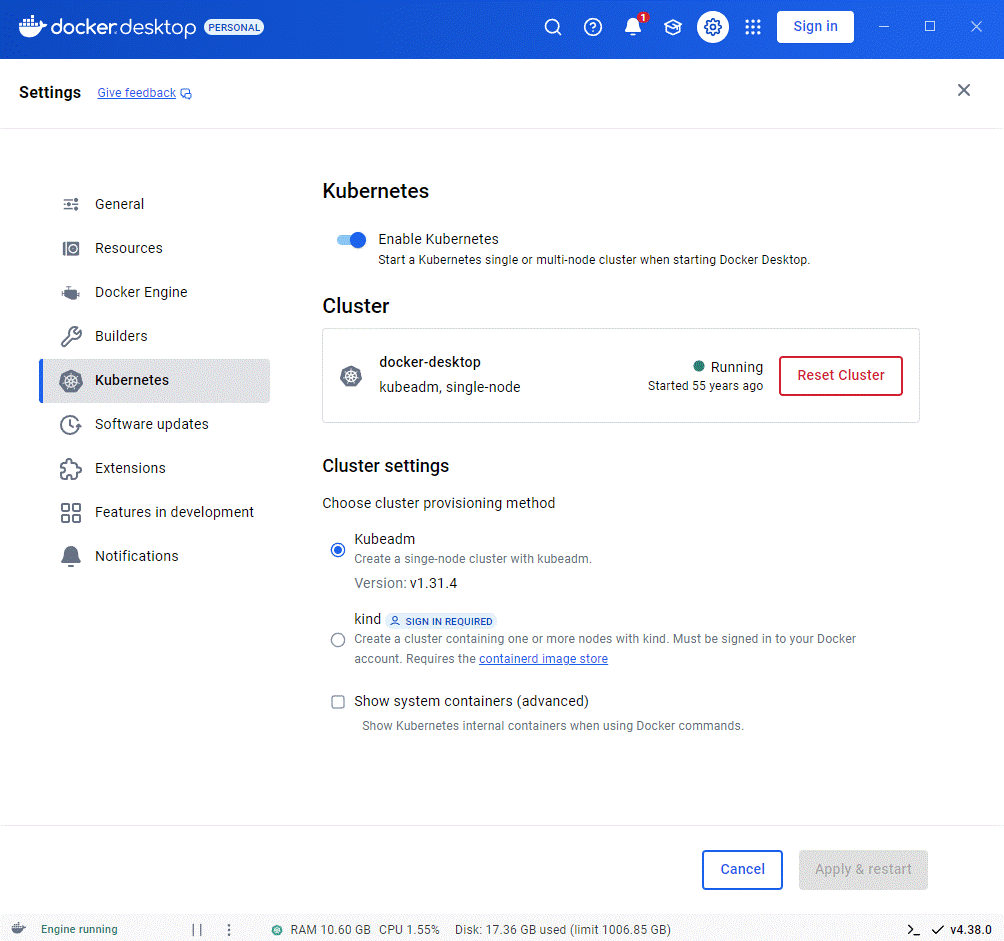
Puis d’activer Kubernetes, toujours dans les réglages. Il faut un peu croiser les doigts pour que ça marche, mais en général ça se passe bien. Sinon quitter et relancer Docker Desktop. Et si vraiment ça ne marche pas, essayer de réinitialiser le cluster Kubernetes (il y un bouton rouge pour ça au même endroit dans l’interface de Docker Desktop). Dans le pire des cas, il y a aussi un bouton « Reset to factory defaults » dans la section Troubleshoot de Docker Desktop en cherchant un peu.
La documentation officielle est ici: https://docs.docker.com/desktop/features/kubernetes
Sachez que Docker Desktop installe automatiquement la version adéquate du CLI kubectl à cet emplacement: C:\Program Files\Docker\Docker\Resources\bin\kubectl.exe. Il pourra donc être utile d’ajouter ce chemin à la variable d’environnement PATH de Windows, ou bien de configurer un profil Windows Terminal en ce sens.
En plus du CLI kubectl, helm est un autre outil utile pour déployer certaines ressources.
A titre personnel, j’utilise un profil Windows Terminal (de type Powershell) configuré ainsi:
& $profile
Set-Alias -Name k -Value "C:\Program Files\Docker\Docker\resources\bin\kubectl.exe"
Set-Alias -Name helm -Value "C:\tools\helm\v3.14.4\helm.exe"
$env:Path = 'C:\Program Files\Docker\Docker\resources\bin\;' + $env:Path
$Env:KUBECONFIG="C:\Users\ericb\.kube\config"
k config use-context "docker-desktop"
k config set-context --current --namespace=default
k get deployments
Je peux ainsi facilement ouvrir un onglet de terminal configuré pour kubectl dans le contexte Kubernetes de Docker Desktop. On notera la présence de la ligne $Env:KUBECONFIG="C:\Users\ericb\.kube\config" qui explicite le fichier de configuration pour accéder au cluster Kubernetes (celui par défaut, donc normalement pas indispensable). C’est pratique à savoir si vous avez besoin de vous connecter à différents clusters (il suffit d’avoir des fichiers de configuration séparés et de sélectionner le bon avec cette variable d’environnement utilisée par kubectl et autres outils de l’écosystème Kubernetes).
On pourra tester la commande kubectl get pods pour confirmer que la communication avec Kubernetes se fait bien. Il est normal de n’avoir aucun pod en résultat si on vient d’installer le cluster. En revanche, si on relance un cluster arrêté, on retrouvera ses pods.
Je conseille aussi vivement l’outil K9s qui est un simple exécutable à lancer depuis un terminal sur la machine hôte, et qui donne une vue synthétique de l’état du cluster Kubernetes. C’est très pratique pour surveiller si un déploiement (ou au contraire la suppression d’un déploiement) est terminé, et tout simplement pour connaître l’état courant du cluster, sans avoir à utiliser le CLI kubectl. Voici le profil Windows Terminal que j’utilise pour pouvoir lancer un onglet directement sur K9s:
& $profile
$env:Path = 'C:\Program Files\Docker\Docker\resources\bin\;' + $env:Path
$Env:KUBECONFIG="C:\Users\ericb\.kube\config"
kubectl config use-context "docker-desktop"
kubectl config set-context --current --namespace=default
C:\tools\k9s\k9s.exe --readonly
A noter: comme l’indique la documentation mentionnée, mettre à jour Docker Desktop ne met pas à jour le cluster Kubernetes. Pour cela, il faut manuellement cliquer sur le bouton « Reset Kubernetes Cluster » dans les réglages de Docker Desktop. Il faudra évidemment avoir en tête que cela réinitialise comme indiqué le cluster (il faudra redéployer les ressources). Pour du développement, il n’est pas primordial d’être constamment sur la dernière version disponible, cela explique probablement ce choix conservateur mais peu pratique de Docker Desktop.
Maintenant que Docker Desktop et Kubernetes sont installés, deux noms d’hôte qu’il est utile de connaître:
kubernetes.docker.internalpeut être utilisé depuis la machine hôte pour communiquer avec le cluster Kubernetes. Par exemple l’API de Kubernetes Control Plane est joignable via https://kubernetes.docker.internal:6443.host.docker.internalpeut être utilisé depuis un container pour communiquer avec la machine hôte. Probablement le nom d’hôte le plus utile des deux à retenir!
Installer le GUI Kube Forwarder
Pas indispensable, mais presque: Kube Forwarder est un utilitaire graphique qui permet de mémoriser des configuration de port forwarding dans Kubernetes. Plutôt que d’avoir à utiliser la commande « kubectl port-forward » et de devoir maintenir une fenêtre terminal par port, cet outil gère la mémorisation des ces ports, et gère la restauration de la redirection de port même si la ressource (ou même le cluster) est temporairement arrêtée/relancée, sans avoir aucune action à faire.
Déployer les premières ressources utiles
Cette section montre comment déployer certaines ressources, à titre d’exemple. Elles peuvent ou non vous être utile selon vos besoin:
- Signoz qui est, pour simplifier, un dashboard compatible avec le récent standard OpenTelemetry (logs, traces et métriques). Pas indispensable, ce sera très utile sur un projet qui publie de la télémétrie compatible OpenTelemetry.
En fait c’est tout car nous déploierons les autres ressources plus tard, via le dernier script, basé sur OpenTofu (fork open source de Terraform). J’ai choisi de déployer Signoz manuellement car sa désinstallation requiert également des étapes manuelles.
Signoz
Installer Signoz consiste à déployer un helm chart. On commencera par créer un namespace dédié qu’on nommera « apm », mais le nom peut être celui de votre choix.
kubectl create namespace apm
helm repo add signoz https://charts.signoz.io
helm repo update
helm --namespace apm install signoz signoz/signoz
L’installation va prendre plusieurs minutes, il faut être un peu patient. Si vous utilisez K9s, par défaut c’est l’espace de nom par défaut qui sera affiché. Comme on déploie Signoz dans un autre espace de nom, pour suivre son déploiement, il faut utiliser la touche « 0 » comme raccourci-clavier pour afficher tous les pods de tous les namespaces (et pour revenir à la vue par défaut, il suffit de faire « 1 », tous ces raccourcis sont décrits via la touche « ? »). Si vous n’utilisez pas K9s, il faut suivre avec une commande telle que « kubectl get pods -n apm ».
Une fois tous les pods visiblement déployés, il faut créer son compte administrateur dans le frontend Signoz. Pour cela, on doit utiliser une redirection de port (port forward) vers le service en question. Avec le GUI Kube Forwarder conseillé plus haut, il suffit de créer celui-ci en sélectionnant le cluster « docker-desktop », le namespace « apm », le service « signoz-frontend » et enfin utiliser le port 3301 à la fois en local et en ressource. Comment sait-on que c’est ce port et ce service ? On peut le découvrir via la commande « kubectl get services -n apm ». Si on ne souhaite pas utiliser Kube Forwarder, la commande serait « kubectl port-forward svc/signoz-frontend -n apm 3301:3301 ».
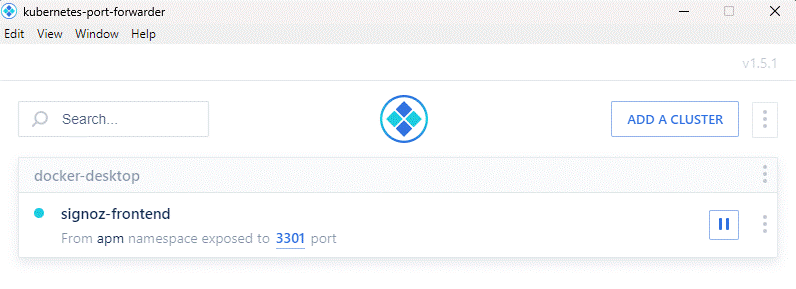
On peut ensuite se rendre à l’adresse http://localhost:3301/ pour accéder au frontend Signoz, créer son compte utilisateur et découvrir l’interface de l’outil.
A noter: si comme moi vous avez interdit les requêtes sortantes via une network policy depuis le namespace apm, il semble que cela fasse boguer l’interface de création du premier compte: le bouton « Get Started » n’est jamais activé. Il suffit de passer par les DevTools du navigateur pour activer le bouton (je ne détaille pas, c’est évident à trouver). Si les requêtes sortantes sont autorisées, le bouton fonctionne sans cette manipulation. Ensuite, il n’y a pas de problème pour utiliser Signoz de cette façon.
Si on désire désinstaller Signoz, c’est normalement aussi simple que cela:
helm uninstall signoz -n apm
Puis surveiller la disparition des ressources depuis K9s (normalement assez rapide). Il va malheureusement rester un pod « chi-signoz-clickhouse-cluster-0-0-0 » qui n’est pas désinstallé automatiquement à cause d’un « finalizer ». C’est expliqué dans la documentation de Signoz: il faut en plus:
kubectl -n apm patch clickhouseinstallations.clickhouse.altinity.com/signoz-clickhouse -p '{"metadata":{"finalizers":[]}}' --type=merge
Si cette commande passe, le dernier pod lié à clickhouse devrait disparaitre rapidement.
Il reste à supprimer les volumes de Signoz pour la persistence de ses données, et son namespace (la suppression du namespace devrait supprimer en cascade les volumes, mais je préfère être explicite sur les volumes):
kubectl -n apm delete pvc -l app.kubernetes.io/instance=signoz
kubectl delete namespace apm
A noter: pour cet article j’ai testé la désinstallation et la réinstallation de Signoz. Une fois réinstallé, on est toujours « authentifié », probablement par un cookie résiduel dans son navigateur, mais il y a alors un bug dans l’interface qui indique que quelque chose ne va pas. Il faut simplement se « Logout » pour retrouver la page de création du premier compte utilisateur.
Déployer l’application en cours de développement
On entre enfin dans le vif du sujet de cet article puisque jusqu’à maintenant je n’ai fait que répéter un condensé de différentes documentations pour installer différents outils.
Pour rappel, le postulat de départ est le suivant:
- On dispose déjà du code source de son application .NET composée de plusieurs services. Chacun avec ses fichiers de configuration (« appsettings.json », « appsettings.Development.json », user secrets, variables d’environnement…)
- On dispose déjà d’un Dockerfile pour chaque service, mais celui-ci n’est pas adapté à un déploiement purement local, il est adapté plutôt à une chaîne de CI/CD qui inclut typiquement les tests unitaires et leur coverage, éventuellement Sonar, etc.
Ce qu’on souhaite, c’est transformer ces Dockerfiles pour n’y conserver que le strict nécessaire (la compilation et le lancement de chaque service) et générer les manifestes pour Kubernetes adaptés à notre cluster local. Dans l’éventualité où on ne dispose pas de Dockerfiles existants, ce n’est pas beaucoup plus compliqué: il suffirait de les générer au lieu de les transformer.
Tout cela pourrait être fait à la main, mais ce serait extrêmement rébarbatif, sans compter qu’il faudrait s’adapter au moindre changement de configuration dans l’application.
L’idée est donc de faire cela sous la forme de scripts (qu’on pourrait rassembler dans un seul script paramétrable). On a besoin de trois actions principales:
- Créer nos images Docker locales (à partir de nos Dockerfiles).
- Générer les manifestes Kubernetes.
- Être en mesure de (re)déployer et (re)lancer tous nos services ou de tous les arrêter en une seule action de notre part.
Malheureusement, on se doute bien que tout ça est très dépendant des spécificités de notre application. Je ne pourrai donc que donner un exemple de principe qu’il faudra adapter.
Pour illustrer et permettre de tester cette approche, j’ai publié sur GitHub une application Demo composée de 3 services (une API, un service console, un frontend basé sur ASP.NET Razor Pages). Le code est minimaliste et ne suit aucune bonne pratique. Ce qu’il fait est même stupide. Il me fallait juste une matière pour les scripts à présenter ici.
L’application dépend de SQL Server, d’Azure Service Bus et d’Azure Blob Storage. Pour SQL Server, comme je l’ai dit plus haut, on considère l’avoir installé sur la machine hôte (il ne sera pas dans Kubernetes). Pour Azure Service Bus et Azure Blob Storage, leur émulateur sera automatiquement déployé dans Kubernetes par notre troisième script grâce à OpenTofu.
Par simplicité, je n’ai pas créé un nouveau dépôt GitHub, j’ai placé les fichiers dans un dépôt qui centralise plusieurs exemples indépendants. On peut donc déjà cloner ce dépôt et vérifier que la solution « Demo » peut être compilée:
git clone https://github.com/eric-b/Samples.git
cd Samples\LocalMicroservicesSample\src\Demo
dotnet build
On peut prendre connaissance de la solution « Demo.sln » dans Visual Studio. On va devoir également enregistrer les user secrets de certains projets (ceux-ci ne sont pas persistés au niveau des fichiers de la solution). Pour chaque projet mentionné, on peut éditer le fichier des secrets via un clic droit sur le projet, « Manage User Secrets »:
Demo.WeatherForecastApi:
{
"SqlDatabase": {
"ConnectionString": "Data Source=localhost;Initial Catalog=Demo;Trusted_Connection=True;TrustServerCertificate=true;"
},
"ServiceBus": {
"ConnectionString": "Endpoint=sb://localhost;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=SAS_KEY_VALUE;UseDevelopmentEmulator=true;"
}
}
Demo.Frontend:
{
"ServiceBus": {
"ConnectionString": "Endpoint=sb://localhost;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=SAS_KEY_VALUE;UseDevelopmentEmulator=true;"
}
}
Demo.BackendService:
{
"BlobStorage": {
"ConnectionString": "AccountName=devstoreaccount1;AccountKey=Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==;DefaultEndpointsProtocol=http;BlobEndpoint=http://127.0.0.1:10000/devstoreaccount1/;"
},
"ServiceBus": {
"ConnectionString": "Endpoint=sb://localhost;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=SAS_KEY_VALUE;UseDevelopmentEmulator=true;"
}
}
Ces fichiers User Secrets sont requis par le script de génération des manifestes qu’on aborde un peu plus loin. En effet le but du script est de générer les manifestes à partir d’une configuration locale censée être fonctionnelle.
On peut également dès maintenant créer la base de données « Demo » dans notre instance locale SQL Server.
On remarquera que chacun des trois services contient un Dockerfile dédié. Si on regarde celui de « Demo.WeatherForecastApi », on voit qu’il dépend de SonarQube avec des arguments de ligne de commande « Docker build ». Celui-ci est parfaitement fonctionnel si vous avez une instance SonarQube, qui peut être installée dans votre cluster Kubernetes local ou même sur un serveur distant. La documentation pour cela est ici. Pour son utilisation depuis un Dockerfile, je me suis appuyé sur cet article de blog:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /source
############ SONAR INITIALIZATION ############
RUN apt-get update && apt-get dist-upgrade -y && apt-get install -y openjdk-17-jre
RUN dotnet tool install --global dotnet-sonarscanner --version 9.1.0
ENV PATH="${PATH}:/root/.dotnet/tools"
ARG SONAR_HOST
ARG SONAR_PRJ_KEY
ARG SONAR_TOKEN
RUN dotnet sonarscanner begin \
/k:"$SONAR_PRJ_KEY" \
/d:sonar.host.url="$SONAR_HOST" \
/d:sonar.token="$SONAR_TOKEN" \
/d:sonar.projectBaseDir="/source"
############ SONAR INITIALIZATION ############
COPY ./Demo.Infrastructure.OpenTelemetry /Demo.Infrastructure.OpenTelemetry
COPY ./Demo.WeatherForecastApi /source
RUN dotnet restore /source
RUN dotnet publish /source -c release -o /app --no-restore
############ SONAR END #######################
RUN dotnet sonarscanner end /d:sonar.token="$SONAR_TOKEN"
############ SONAR END #######################
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
COPY --from=build /app ./
ENTRYPOINT ["dotnet", "Demo.WeatherForecastApi.dll"]
En supposant que SonarQube est déployé dans notre cluster local et qu’un port forward adéquat est en place, que le projet « Demo » a été configuré dans SonarQube et qu’on dispose d’un sonar token, la commande à lancer pour compiler le Dockerfile serait (depuis le dossier qui contient le Dockerfile en question):
docker build -t tmp-test -f Dockerfile-BackendService --build-arg SONAR_HOST="http://host.docker.internal:9000" --build-arg SONAR_PRJ_KEY="Demo" --build-arg
SONAR_TOKEN="..." .
Bien que je ne conseille pas de le tester vous-même, car utiliser SonarQube en local n’est pas l’objet de l’article, on pourra deviner qu’au mieux, si la compilation du Dockerfile fonctionne, elle est beaucoup plus lente que ce qu’elle pourrait être sans SonarQube. Et plus typiquement, Sonar est un serveur distant et on ne connait pas le token du projet puisqu’il est configuré au niveau de la chaîne CI/CD, donc on serait juste incapable d’utiliser ce Dockerfile en l’état.
Le Dockerfile ci-dessus pourrait être transformé pour ne conserver que ce qui est utile à l’exécution locale de l’application:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /source
COPY ./Demo.Infrastructure.OpenTelemetry /Demo.Infrastructure.OpenTelemetry
COPY ./Demo.WeatherForecastApi /source
RUN dotnet restore /source
RUN dotnet publish /source -c release -o /app --no-restore
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
COPY --from=build /app ./
ENTRYPOINT ["dotnet", "Demo.WeatherForecastApi.dll"]
Script 1: transformer les Dockerfiles
Plutôt que d’avoir à maintenir plusieurs variantes de Dockerfiles, le « vrai » pour le CI/CD et le « faux » pour les tests en local, l’idée est donc de faire un premier script dont l’unique tâche est de détecter les « vrais » et uniques Dockerfiles de l’application, et en faire une copie transformée. Cette copie serait stockée en dehors du dépôt git (et pourrait ne pas être conservée puisqu’on sait la générer). Ce même script pourra déclencher la commande docker build sur le fichier transformé. A la fin, le résultat est qu’on a l’image de notre application compilée, correspondant à l’état de notre code en local (donc pas nécessairement poussé sur git), dans le cache local d’images de Docker Desktop.
J’ai publié sur GitHub un exemple d’un tel script: LocalMicroservicesSample/scripts/1-docker-build-images.linq
Par simplicité, il s’agit d’un script LinqPad, vous pouvez tout à fait utiliser son édition gratuite s’il s’agit de tester ce script, sinon il suffit de convertir le script en programme console.
Après l’exécution de ce premier script, on devrait trouver les Dockerfiles générés dans le dossier demo/Dockerfiles. Et les images seront disponibles dans le cache de Docker Desktop. Il ne reste plus qu’à utiliser ces nouvelles images, soit avec docker-compose, soit avec Kubernetes. C’est l’étape suivante avec un script capable de générer les manifestes pour Kubernetes.
Script 2: générer les manifestes Kubernetes
Ce script est de loin le plus élaboré. Il est très dépendant de la solution, notamment pour la gestion des paramètres de l’application qu’on doit adapter.
L’exemple de ce script est ici: LocalMicroservicesSample/scripts/2-k8s-generate-manifests.linq
Celui-ci part des Dockerfiles pour identifier les différents services, puis pour chacun génère les manifestes adéquats:
- StatefulSet: J’ai choisi de générer un StatefulSet au lieu d’un Deployment pour avoir un nommage plus déterministe une fois ce type de ressource déployé.
- ConfigMap: Pour chaque service, on aura deux config maps. Le premier pour la configuration « locale » du service (équivalent au fichier « appsettings.Development.json »), le second pour la configuration d’OpenTelemetry Collector qu’on déploie en sidecar.
- Secret: Si le service contient des paramètres de configuration secrets, ils sont déployés via ce type de ressource.
- Service: Si le service expose un serveur HTTP (Kestrel), on créera le service Kubernetes associé.
- Namespace: On déploiera tous les services de l’application dans un namespace Kubernetes dédié.
À côté du script, on trouvera un fichier « .env » qu’on utilisera pour remplacer certains paramètres de configuration. Par exemple, la chaîne de connexion à la base de données, au service bus ou à azurite. Noter que le champ « Password » de la base de données contient une variable ${sql_db_password}. Il s’agit d’une variable qui sera remplacée par OpenTofu. Ce fichier ne contient donc pas réellement de secret, et si tel était le cas, on pourrait le placer ailleurs, éloigné du script, pour éviter de l’enregistrer dans un dépôt Git.
La génération des manifestes s’appuie sur des modèles placés dans le répertoire « 2-templates/k8s ». Si on les regarde, ceux-ci contiennent deux types de variables qui seront interpolées: les variables telles que {appName} sont gérées par notre script de génération du manifeste. En sortie, cette variable est remplacée par le nom du service, dans le manifeste généré; les variables telles que ${namespace} sont gérées par OpenTofu au moment du déploiement du manifeste généré dans Kubernetes.
Si on exécute le script, les manifestes devraient être générés dans le dossier demo/k8s.
Script 3: deployer les manifestes Kubernetes
La dernière étape est d’être en mesure de déployer nos ressources dans Kubernetes, et ce de la manière la plus automatisée possible car c’est l’action qu’on effectuera le plus souvent au cours de développement de l’application.
Ce script a en fait plusieurs actions (une action cible paramétrée à chaque exécution) et utilise deux outils:
- RestartAll: cette action exécute le déploiement des ressources avec OpenTofu, puis utilise la librairie Kubernetes Client pour .NET pour définir 0 réplica pour chaque service, attend que cette cible soit atteinte, puis définit 1 réplica cible. Ces trois actions en une garantissent qu’on redéploie la dernière version de nos images Docker et qu’on redémarre les applications, qu’il y ait ou non des changements de configuration.
- StopAll: cette action invoque l’API de Kubernetes pour définir 0 réplica pour chaque service.
En plus de ces deux actions, qui sont celles qu’on utilise le plus souvent, on a deux autres actions de « support » utilisées plus rarement:
- OpenTofuInit: lance la commande
initd’OpenTofu. Cette commande n’est à faire qu’une seule fois. - OpenTofuDestroyAll: lance la commande
destroyd’OpenTofu, qui supprime les déploiements de notre application.
Pour la partie OpenTofu, il y a deux projets:
- dev-dependencies: les ressources transverses dont notre application dépend, et pouvant être utiles à d’autres applications qu’on développerait. L’intérêt de les séparer de l’application est qu’on peut facilement « détruire » les ressources de notre application tout en conservant ces ressources transverses. Ce projet va déployer Azure Service Bus Emulator, Azurite et Prometheus. Noter la présence également d’un helm chart « Reloader »: ce composant va déclencher automatiquement le redémarrage d’Azure Service Bus Emulator dès que l’on modifie son Config Map (là où on doit déclarer les files et les topics de notre application).
- demo: pour déployer les services qui composent notre application.
L’intelligence de cette partie n’est donc pas dans le script qui est très simple, mais dans les projets OpenTofu (aka Terraform). Ces fichiers sont « statiques » et évolueront peu une fois créés (étape manuelle, mais également assez facile si on suit la documentation officielle).
Ces projets sont très basiques: ils s’appuient sur deux providers « kubectl » et « helm ». Le premier sert à exécuter la commande kubectl apply avec nos manifestes. Le second sert à déployer un helm chart.
Afin de limiter le risque de publier les secrets dans un dépôt Git, certains fichiers sont placés loin du projet OpenTofu, dans les dossiers « %APPDATA%\OpenTofu\dev-dependencies » et « %APPDATA%\OpenTofu\demo ». Chaque dossier contient le chemin où stocker l’état déployé (l’état est un fichier contenant tous les manifestes avec les valeurs interpolées et donc les secrets), ainsi que certaines variables secrètes. Sinon, tout le reste se trouve dans le dossier principal du projet OpenTofu. Tout est expliqué en détail dans le fichier « README.md » de chaque projet.
Fichier « %APPDATA%\OpenTofu\dev-dependencies\state.config »:
path = "C:/Users/.../AppData/Roaming/OpenTofu/dev-dependencies/state/terraform.tfstate"
Fichier « %APPDATA%\OpenTofu\dev-dependencies\terraform.tfvars »:
sqlserver_sa_password = "..."
La variable sqlserver_sa_password est requise par Azure Service Bus Emulator. Il faut donc s’assurer que notre instance locale de SQL Server dispose bien d’un compte « sa » (super admin) et que les connexions TCP/IP sont autorisées. Par défaut elles ne le sont pas, cela se change dans SQL Server Configuration Manager, dans la partie « SQL Server Network Configuration ». Pour la création du compte « sa », cela peut se gérer via SQL Server Management Studio, dans les propriétés du serveur, partie « Security ». Une fois le compte disponible, il faut définir son mot de passe au niveau du login « sa » et activer « Login » dans la partie « Status » de ce login. N’oubliez pas de tester l’authentification avec le compte « sa » et son mot de passe, depuis SQL Server Management Studio, pour vérifier au moins ce point.
Fichier « %APPDATA%\OpenTofu\demo\state.config »:
path = "C:/Users/.../AppData/Roaming/OpenTofu/demo/state/terraform.tfstate"
Fichier « %APPDATA%\OpenTofu\dev-dependencies\terraform.tfvars »:
sqlserver_demo_container_password= "..."
La variable sqlserver_demo_container_password est le mot de passe du login « demo » utilisé par notre application. Il faudra vous assurer de créer la base de données « demo » et le login « demo » ayant accès à cette base (avec le role db_owner).
Enfin, il faut ajouter une variable d’environnement TF_VAR_azurite_hostpath avec une valeur telle que (à adapter): /run/desktop/mnt/host/c/tmp/demo-azurite (et créer le dossier correspondant sur c:\tmp\demo-azurite). C’est ainsi qu’on configure où azurite stockera ses fichiers, via un volume persistant lié à la machine hôte. Si vous vous interrogez sur la bizarrerie de ce chemin, c’est lié au fonctionnement de Docker Desktop avec WSL.
Une fois ces pré-requis en place (OpenTofu installé et fichiers secrets créés comme indiqués), on devra lancer la première initialisation d’OpenTofu via l’action OpenTofuInit du script (modifier la valeur de la variable programAction).
L’exemple de ce script est ici: LocalMicroservicesSample/scripts/3-k8s-restart-all-pods.linq
Si tout se passe bien, OpenTofu télécharge les providers « helm » et « kubectl ».
Puis on peut relancer le script avec l’action RestartAll pour voir la magie s’opérer.
Ce sera un peu long la première fois car les conteneurs devront être téléchargés. Les fois suivantes, ce devrait être très rapide. Il est utile de surveiller la progression du démarrage (ou de l’arrêt) des ressources dans K9s. En effet le script se termine bien avant que Kubernetes n’applique tous les changements requis.
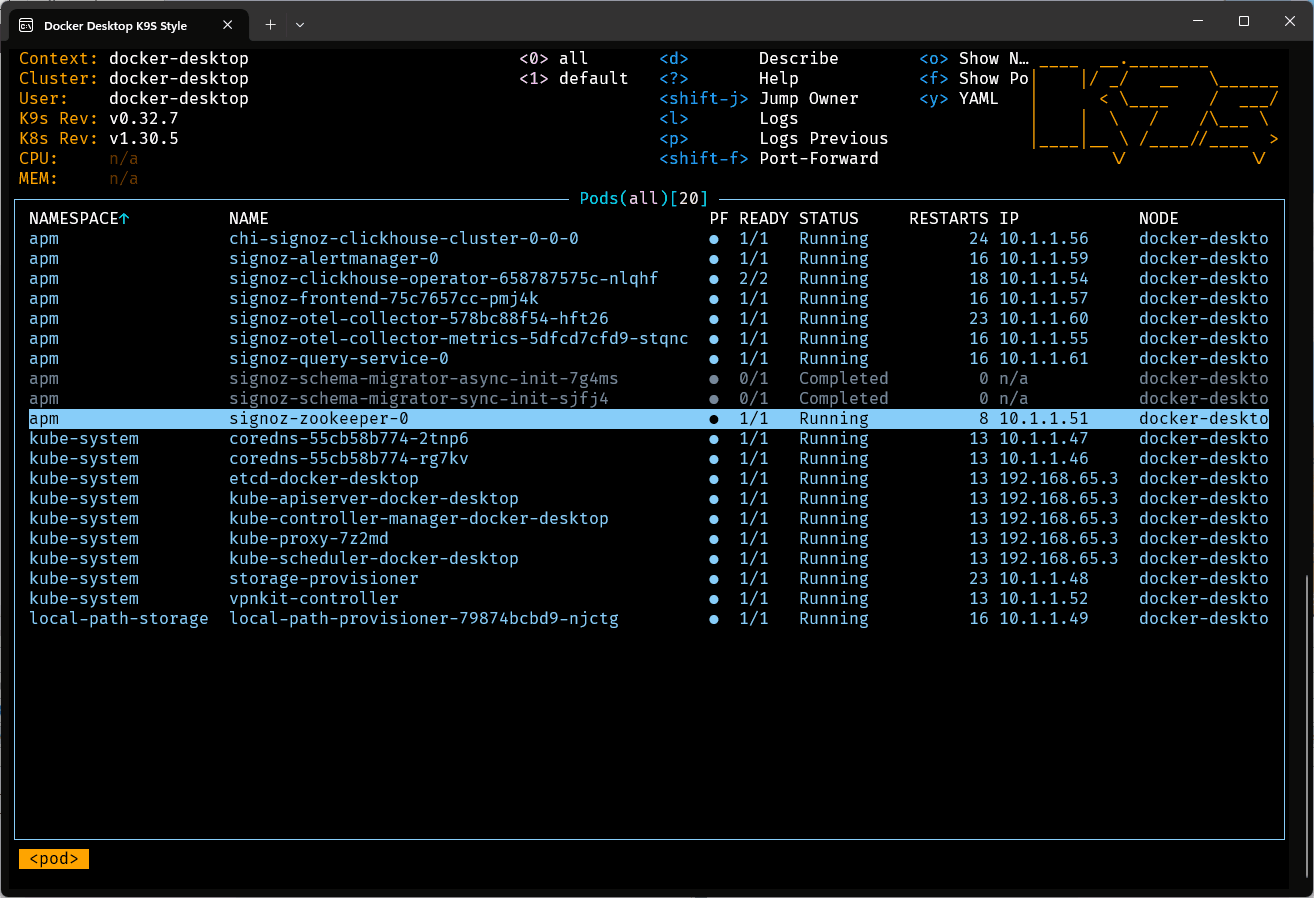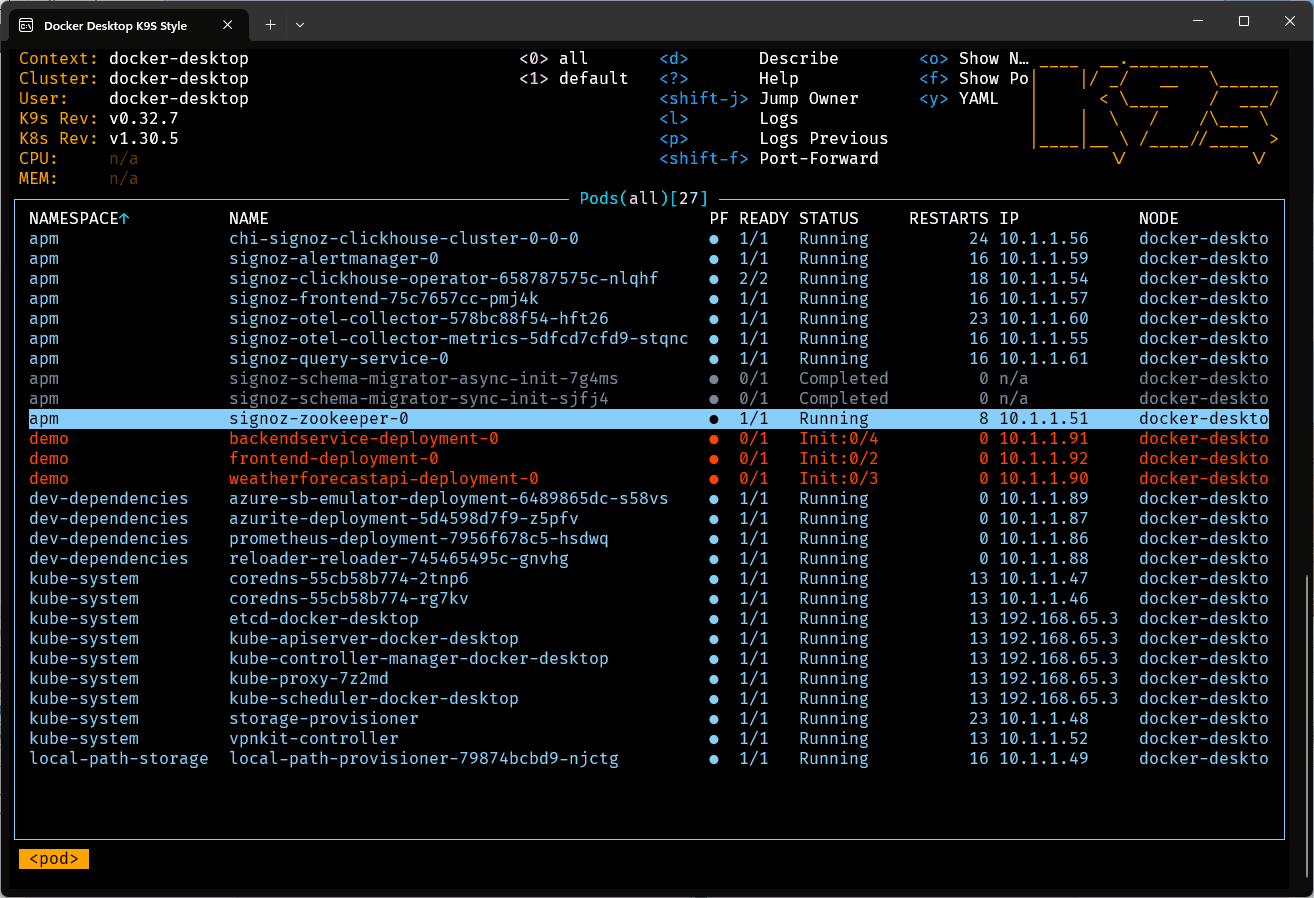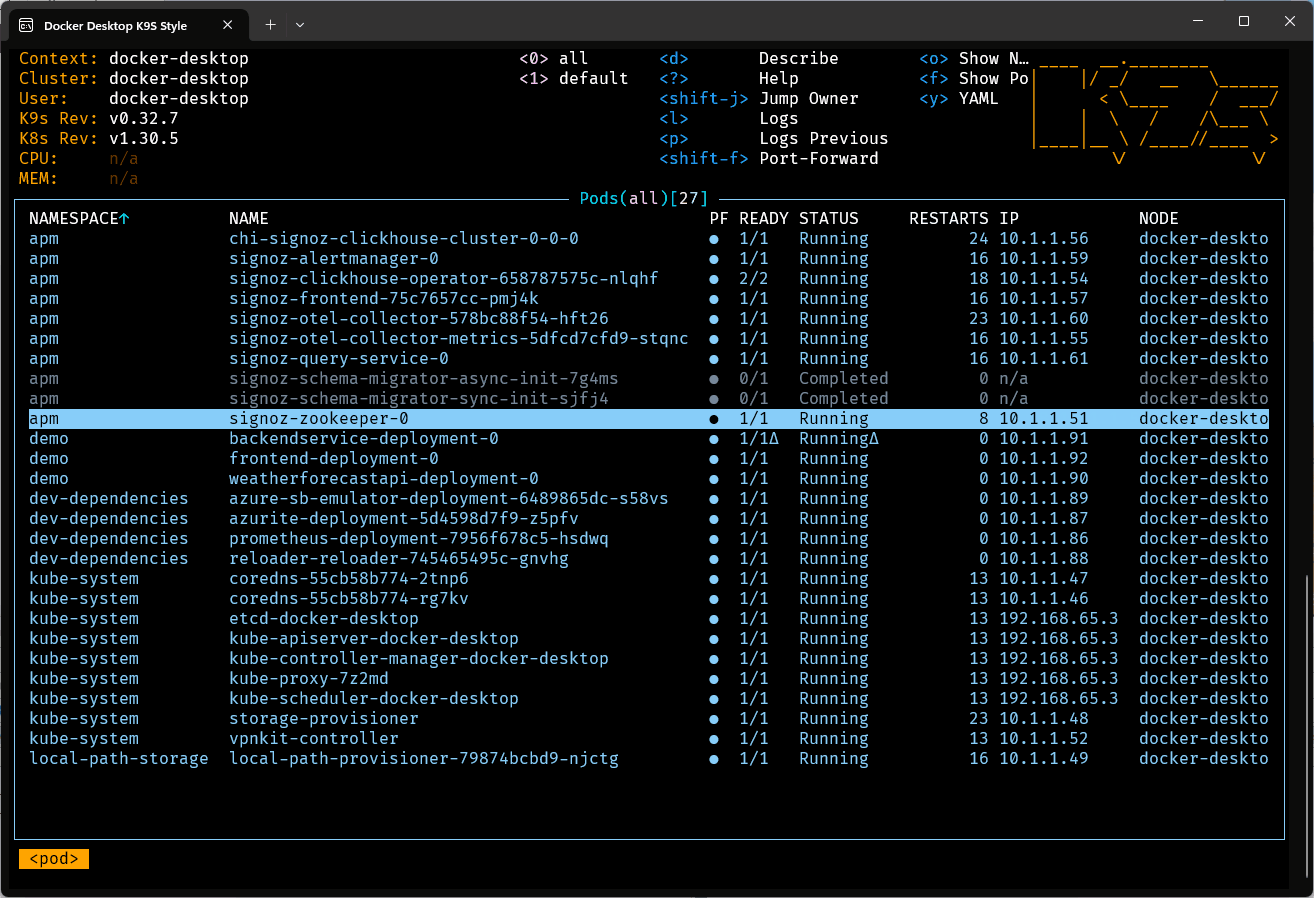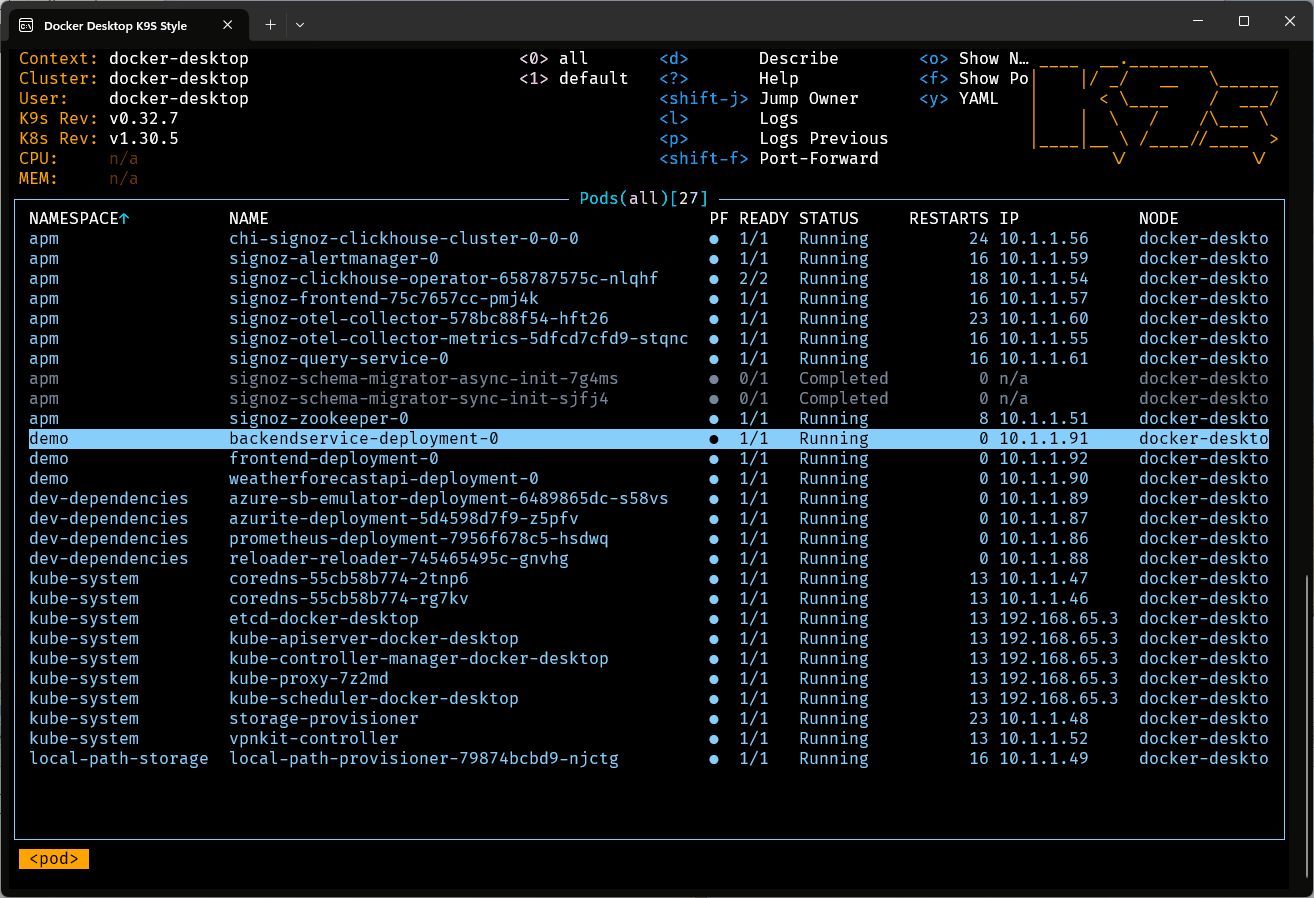
Une fois le déploiement terminé, on peut créer quelques redirections de port dans Kube Forwarder:
- azurite-service: sur le port 10000
- azure-sb-emulator-service: sur le port 5672
- prometheus-service: sur le port 9090
- weatherforecastapi-service: sur le port distant 8080, local 5110
- frontend-service: sur le port distant 8080, local 5255
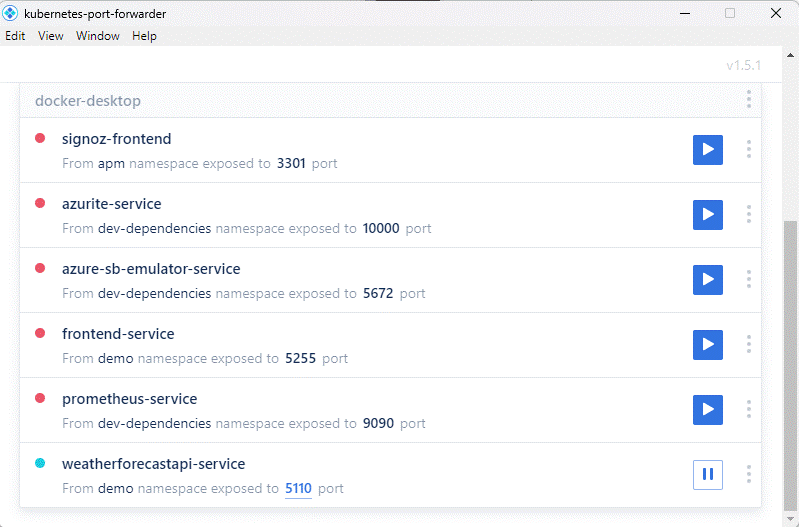
On peut commencer par vérifier que notre API fonctionne, en activant la redirection de weatherforecastapi-service, et en allant sur http://localhost:5110/swagger. On doit pouvoir tester l’API et obtenir des valeurs d’exemple. En cas d’exception (par exemple une erreur d’accès à SQL Server), le détail sera retourné.
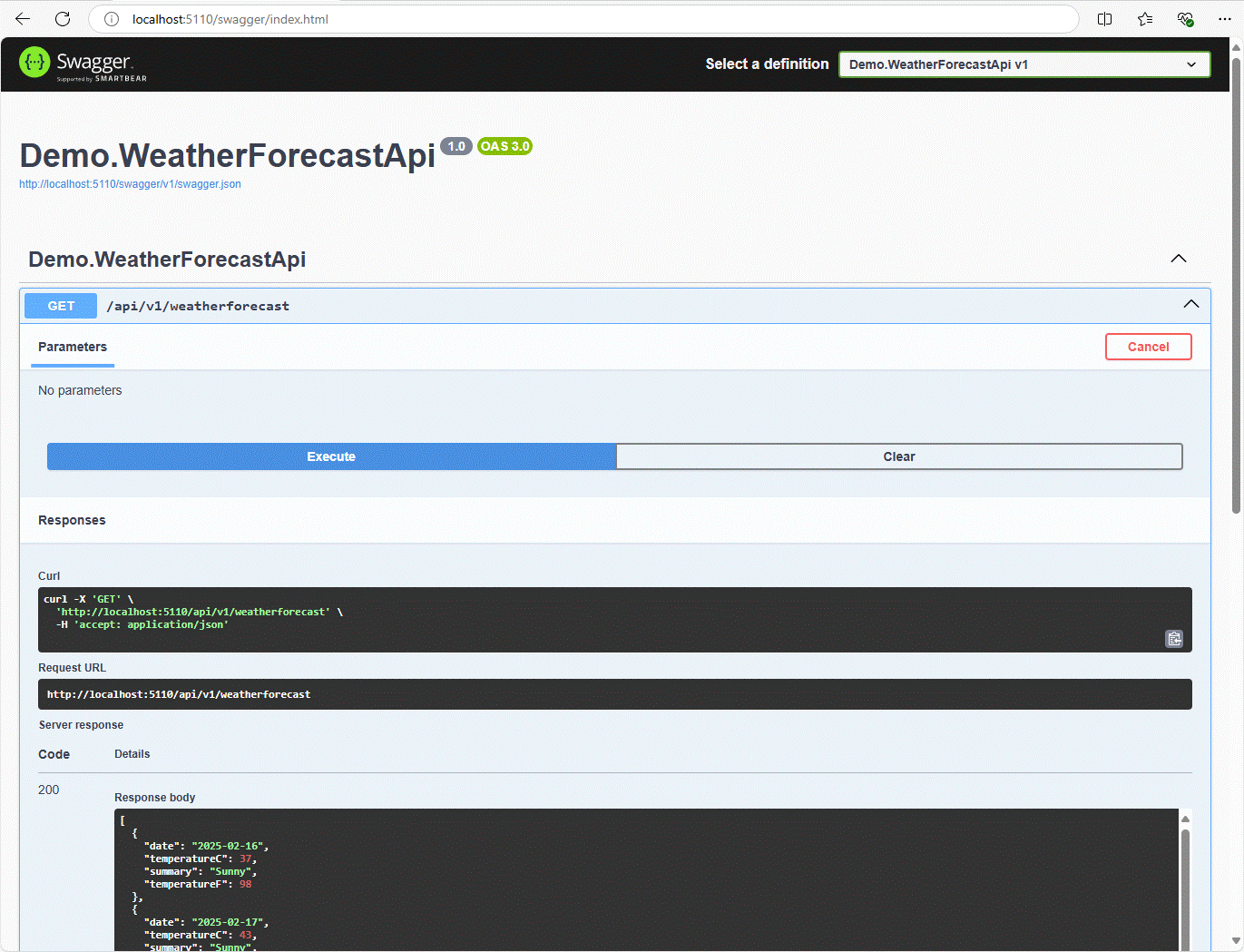
Si tout fonctionne, on peut désactiver la redirection vers cette API, et activer celle de frontend-service pour se rendre sur http://localhost:5255. Dans la page qui s’affiche, cliquer sur le bouton « Trigger ».
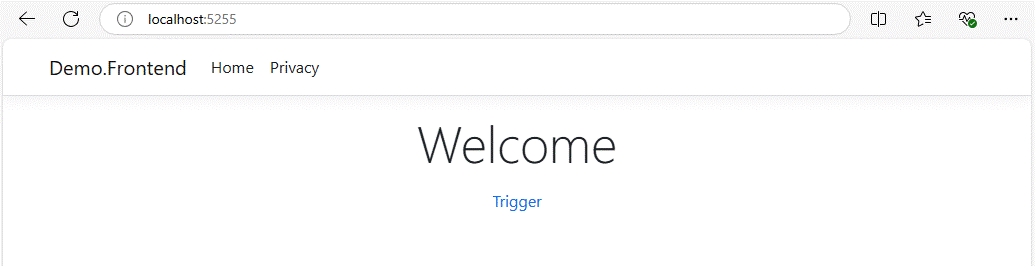
Le bouton n’offre aucun feedback, je ne me suis vraiment pas embêté! En revanche, il déclenche une mini réaction en chaîne: il envoie un message dans une file du Service Bus, ce message est consommé par backendservice qui va appeler en l’API HTTP weatherforecastapi-service que l’on a testé en premier. La réponse de l’API sera stockée dans un blob.
On pourrait vérifier tout cela en allant regarder dans la sortie console de chacun de ces services, mais il y a mieux: aller consulter les logs centralisés dans l’outil Signoz qu’on a déployé dans notre cluster. Activez la redirection du port de Signoz dans Kube Forwarder, puis allez sur http://localhost:3301. Dans l’onglet « Logs », on devrait voir pas mal de choses (les logs dans Signoz sont affichés de bas en haut, le plus récent en premier):
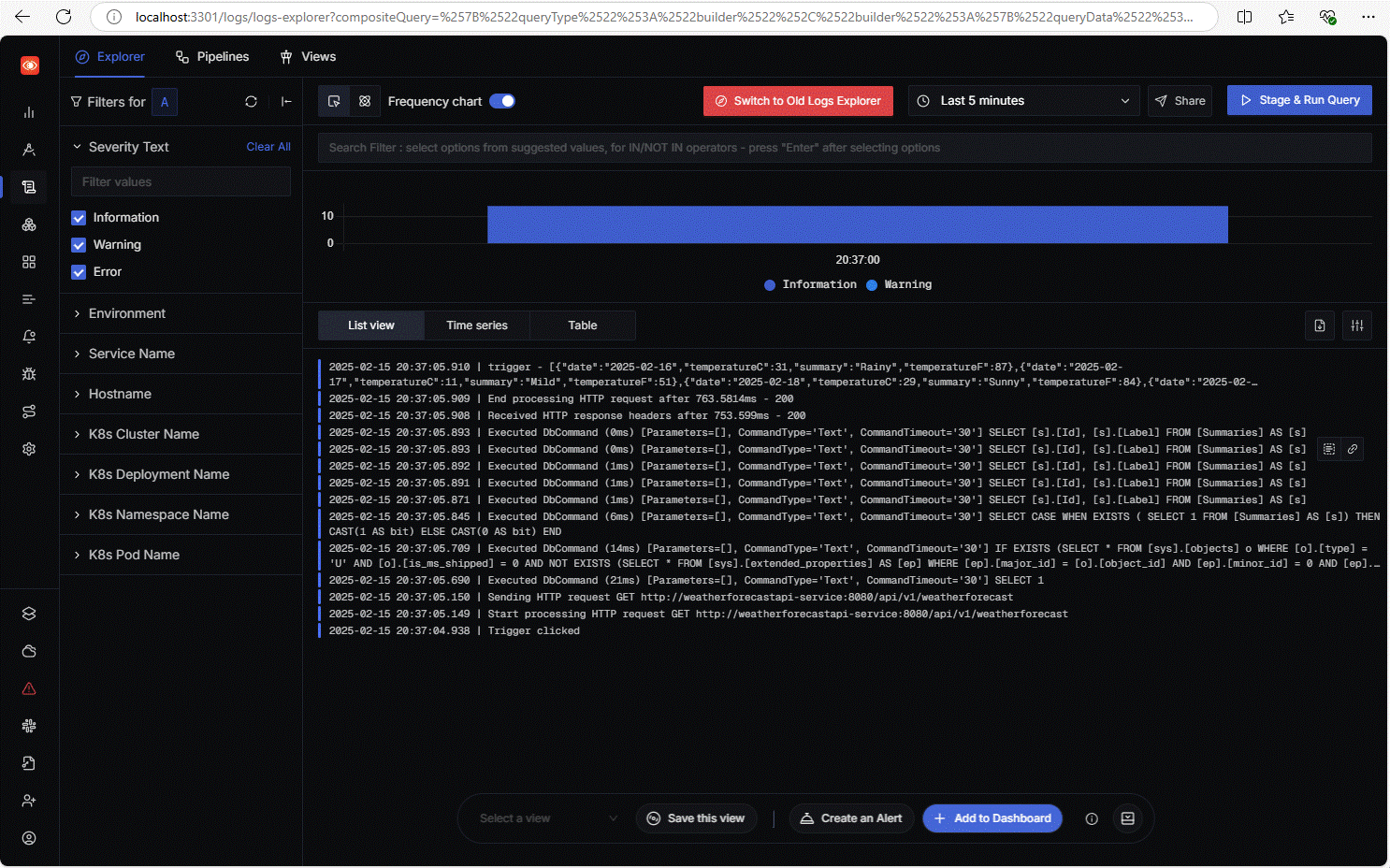
La vue par défaut des logs dans Signoz ne contient pas la colonne qui identifie le service émetteur du log, donc il est difficile de voir qui fait quoi ici. On pourrait bien sûr ajouter la colonne du nom de service dans cette vue. On peut également aller voir l’onglet Traces, où l’on devrait trouver plusieurs traces de nos services distribués. En cliquant sur l’une des plus pertinentes, on devrait obtenir une vue similaire à ceci, qui montre bien la petite chorégraphie des services telle que je l’ai décrite un peu avant (noter que dans la capture suivante, je n’ai pas déplié le détail de toutes les traces):
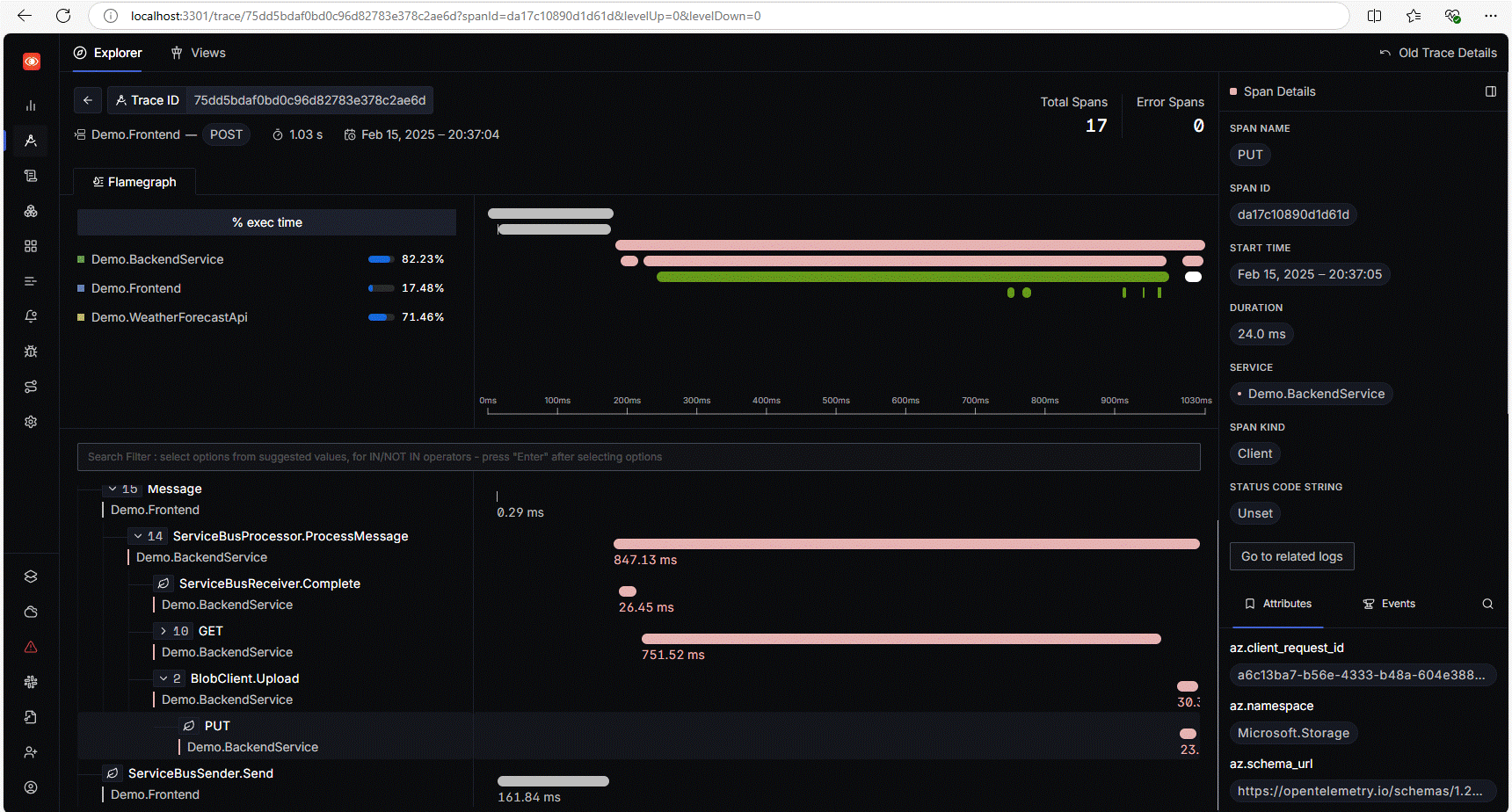
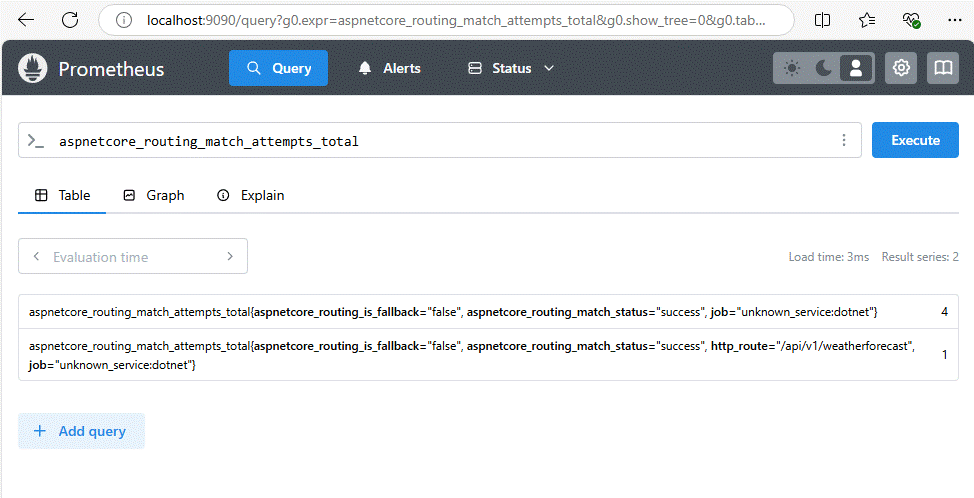
On peut vérifier que les métriques de notre application remontent bien via OpenTelemetry jusqu’à Prometheus: activer la redirection du port 9090 de Prometheus dans Kube Forwarder et allez sur http://localhost:9090. On peut chercher par exemple la métrique aspnetcore_routing_match_attempts_total qui montre bien qu’elle vient de notre API:
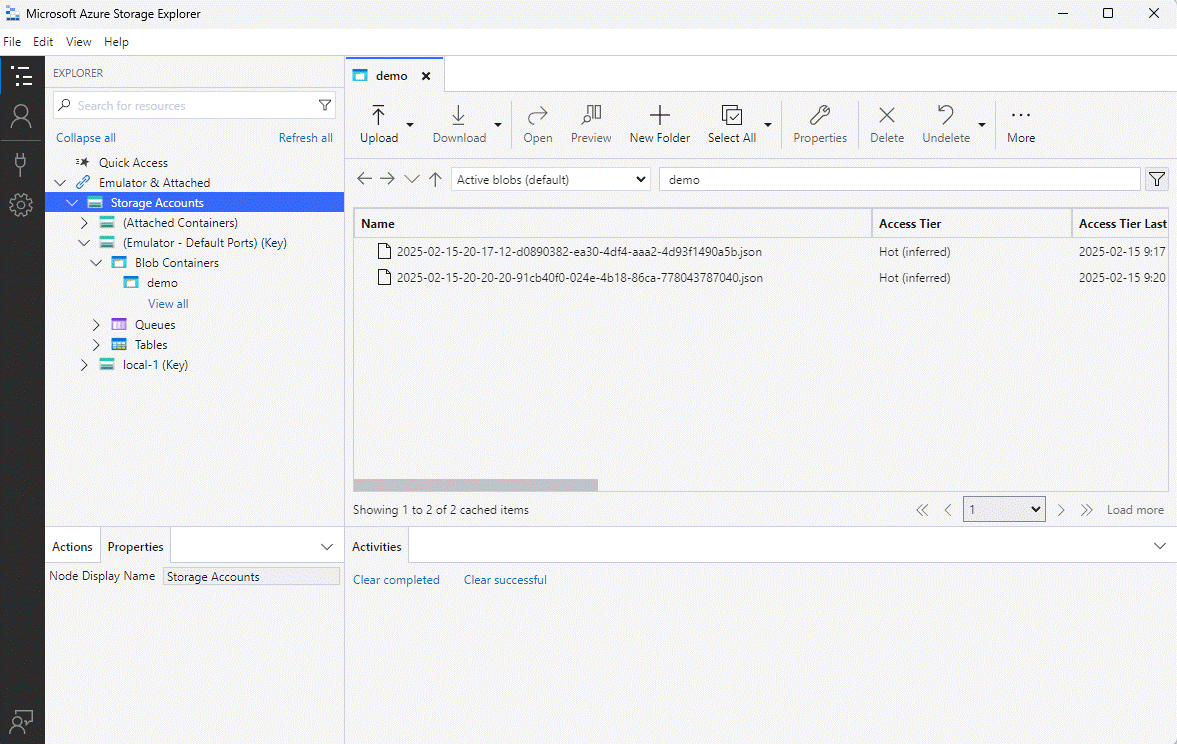
Pour terminer, on peut vérifier qu’on trouve bien nos blobs grâce à Microsoft Azure Storage Explorer (installé en local). Il faut s’assurer avant de le lancer d’activer la redirection du port d’azurite dans Kube Forwarder:
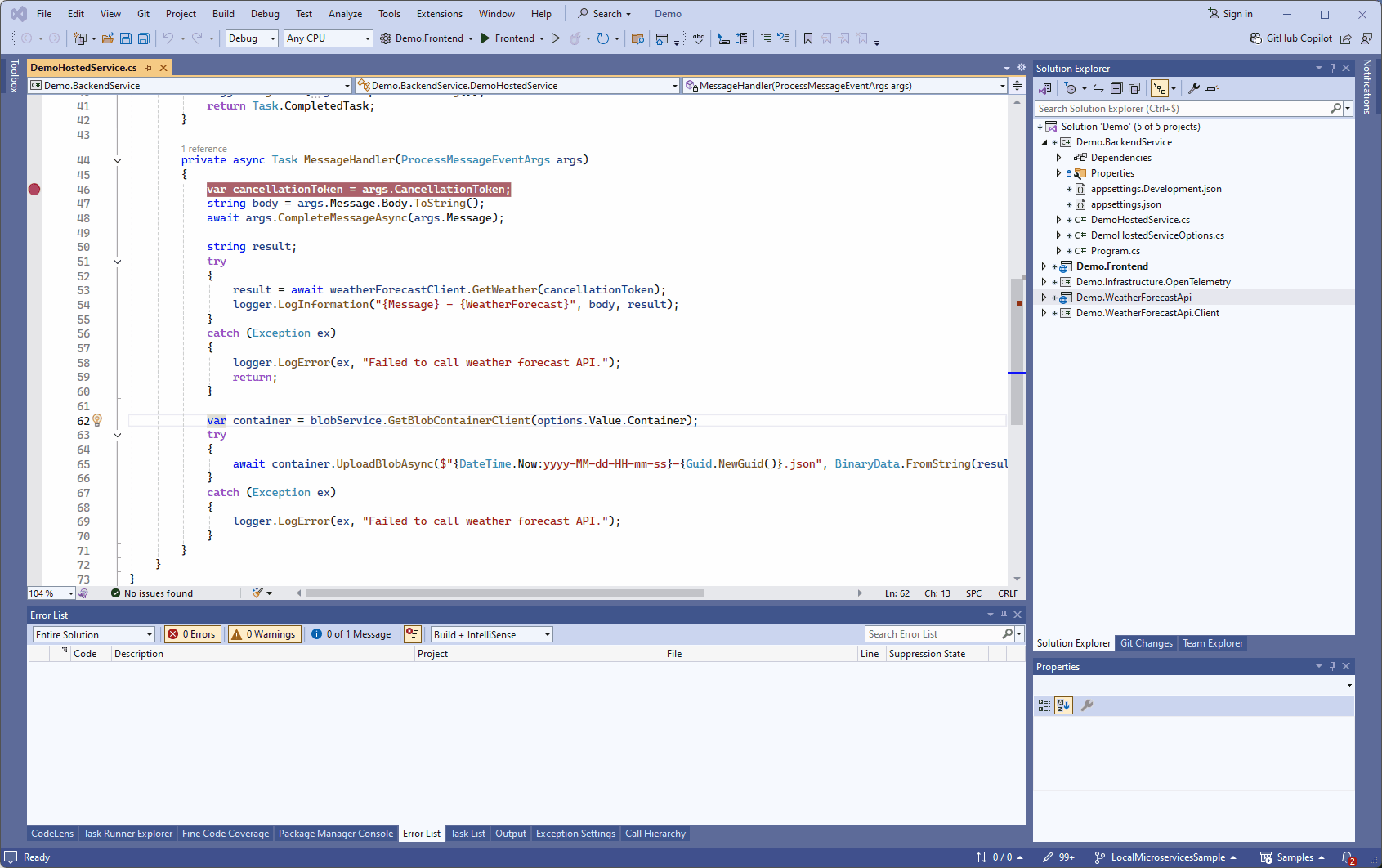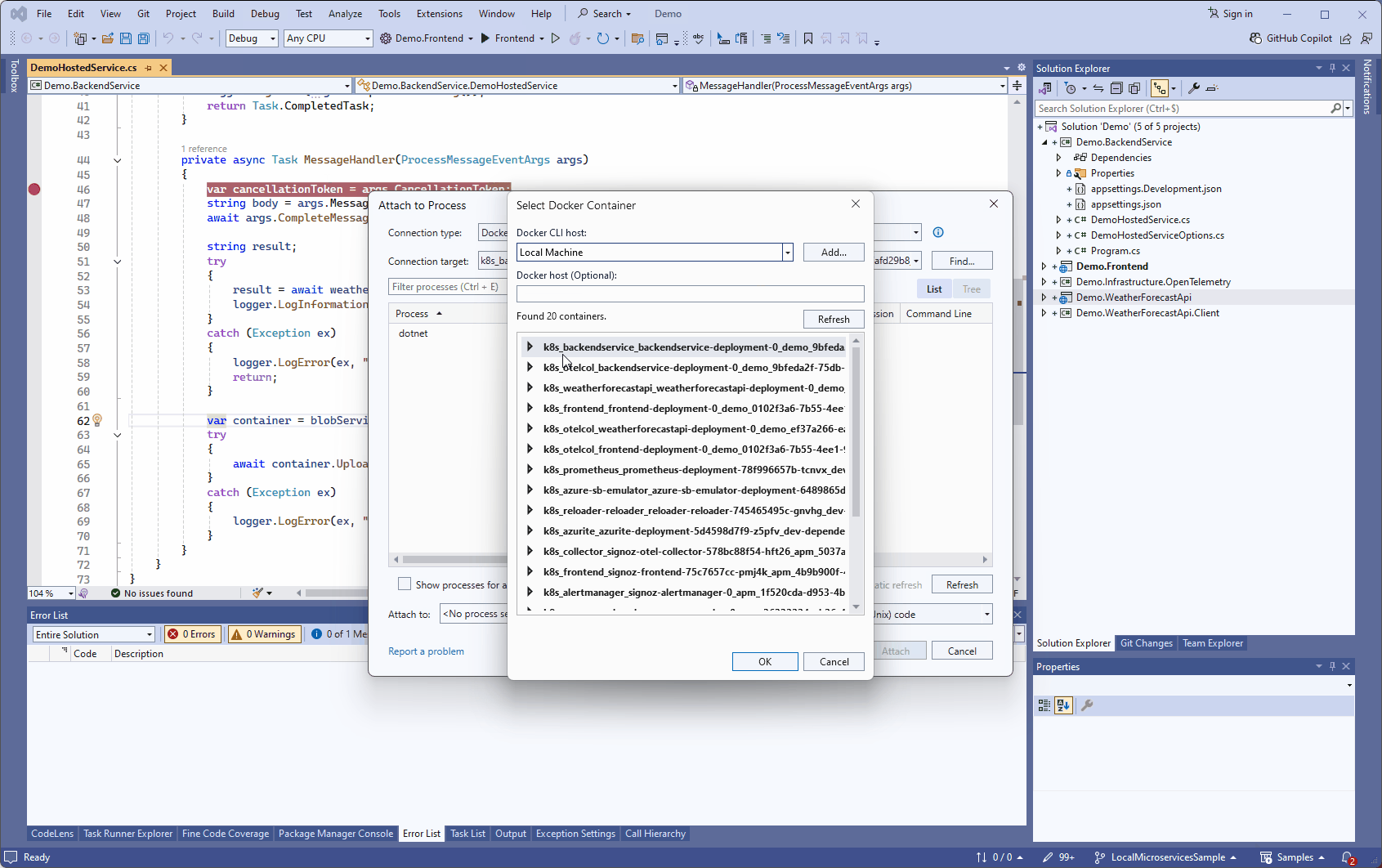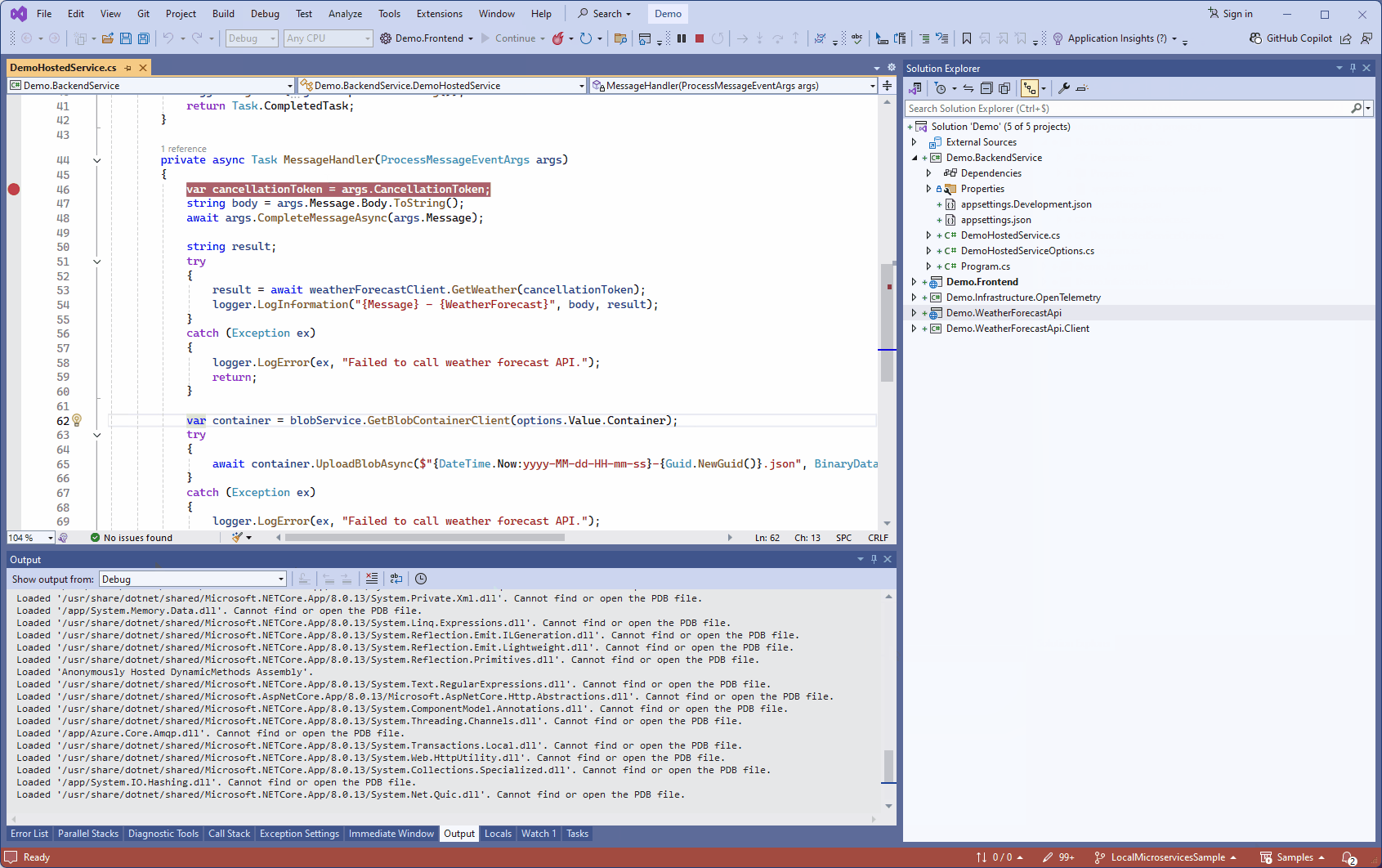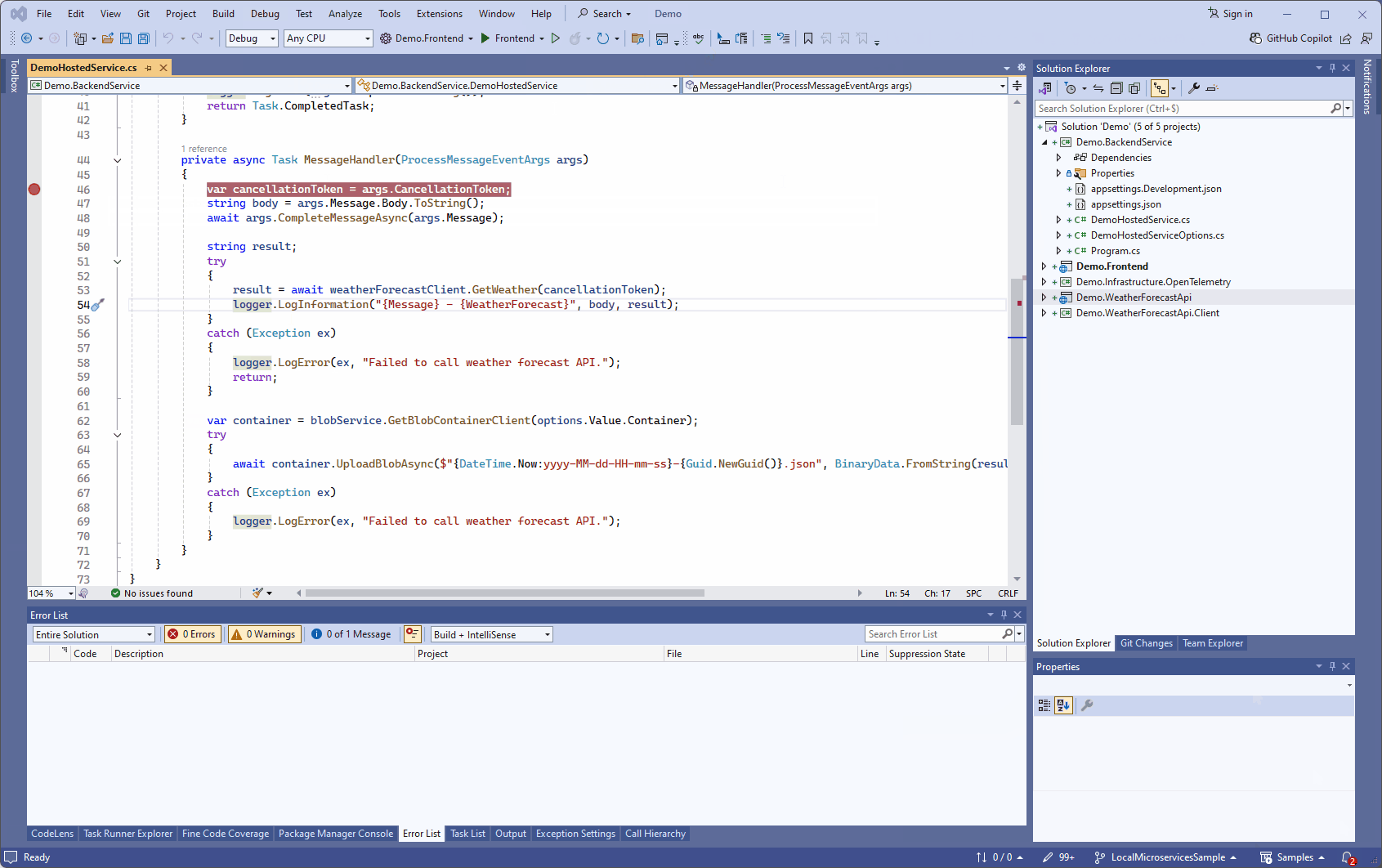
Si on souhaite déboguer un service depuis Visual Studio, on peut toujours le faire en s’attachant au processus .NET qui tourne dans le conteneur Docker:
En développant cette méthode, on pourrait même alterner les versions déployées. Les images Docker sont déjà taguées en fonction de l’heure et de la date par notre script. Si on en tirait parti, on pourrait facilement redéployer dans Kubernetes une version testée auparavant, et avoir en local le code actuel (cependant pour que l’on puisse déboguer les services dans Kubernetes depuis Visual Studio, le code local doit correspondre exactement à celui déployé). Je n’ai pas été jusque là dans cet exemple pour rester simple, mais ce ne serait pas très compliqué à gérer.
Evidemment tout cela n’est qu’un exemple. L’idée est de montrer la flexibilité que l’on obtient en déployant nos ressources au sein d’un ensemble cohérent grâce à cette méthode, et de tirer parti de nombreux outils open source qui, pour beaucoup d’entre eux, ont été largement adoptés par l’industrie du logiciel.