
Ce blog a été migré plusieurs fois. A chaque fois, je mûri un peu ma démarche, sans que cela ne me prenne trop de temps personnel.
Motivations de ce changement
La première fois, je payais une somme assez modique pour gérer la publication de contenu en ligne. Ça a bien fonctionné quelques années jusqu’à ce que ce service, que je ne nommerai pas, a revendu mes données (je le sais car j’ai fourni une adresse e-mail unique à ce service, et j’ai commencé quelques années après à recevoir de nombreux spams sur cette adresse), et a injecté sur les pages de mon blog des scripts de tracking dont celui de Facebook que je n’avais jamais moi-même intégré. Il fait peu de doute que ce fournisseur de service était davantage rémunéré par des annonceurs et autres brokers de données personnelles que par ses propres abonnés payants.
Cela a été le premier déclic pour migrer vers une solution que je maitriserai davantage: j’avais choisi la solution de Simple Hosting WordPress de Gandi.
La dernière migration date de ce mois de novembre pour partir vers Cloudflare Pages. C’est en gros un serveur de pages statiques, intégré à un dépôt GitHub.
Pourquoi ce changement: grâce à Grafana et Blackbox Exporter pour Prometheus sur un serveur local privé, je surveille que le blog est bien accessible, et que son contenu ne semble pas anormal, par exemple suite à un piratage. Et dernièrement, l’hébergement de Gandi était devenu très peu fiable (un problème de certificat TLS je pense, mais que je n’avais absolument pas à gérer). C’était l’occasion pour passer à Cloudflare Pages, une solution entièrement gratuite et qui, je l’espère, devrait s’avérer beaucoup plus fiable que Gandi. Et si un jour ce n’est plus le cas, le fait d’être passé à un site statique facilitera la migration vers une autre solution.
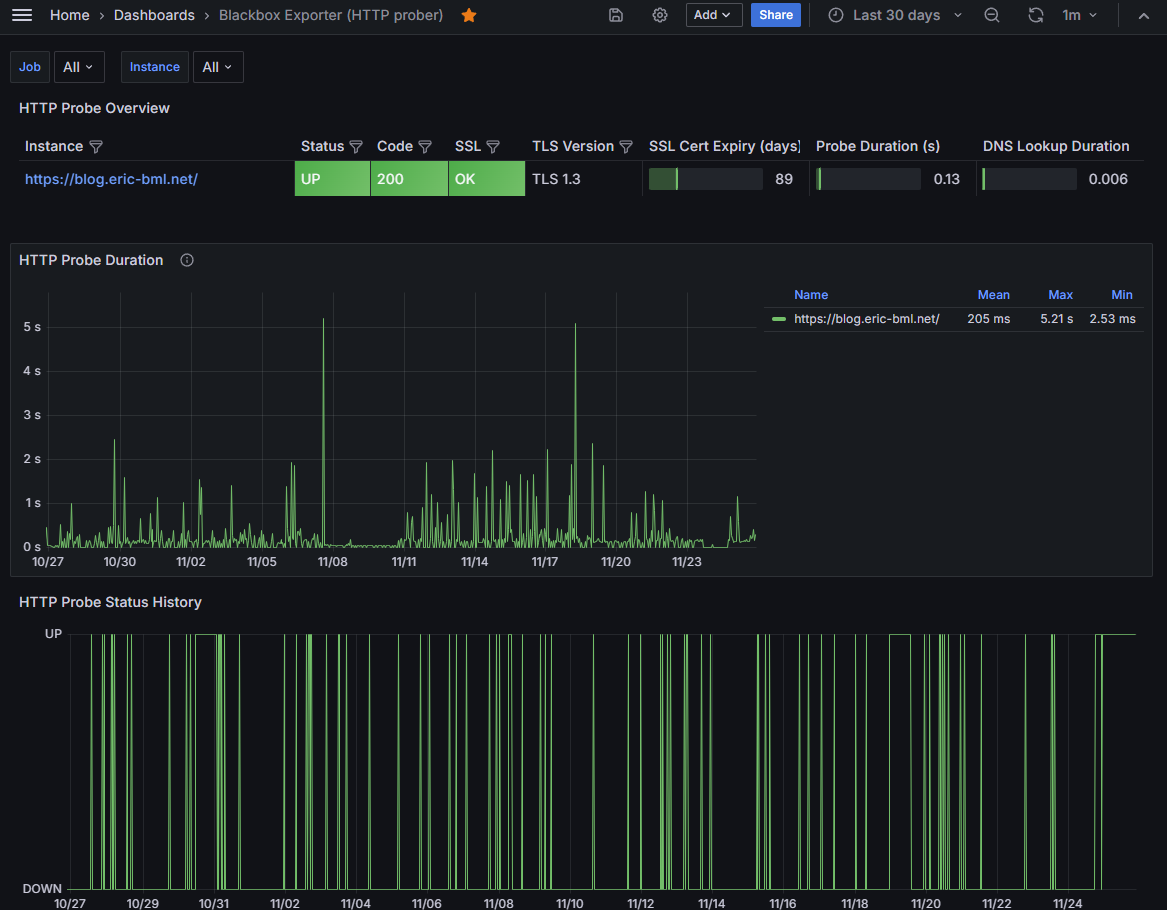
Sur la capture ci-dessus, le graphique du bas « HTTP Probe Status History » montre que le site n’était souvent pas joignable (quelle qu’en soit la raison). À l’extrémité droite du graphique, correspondant au 24 novembre, le statut reste « UP » de façon stable: c’est suite à la migration vers Cloudflare Pages.
Autre avantage de passer à un site statique: la sécurité, les performances, et des économies. Le site WordPress n’a plus besoin d’être accessible sur Internet, il n’y a plus besoin de base MySql et d’application PHP disponible en permanence pour le servir, et le coût d’un hébergement de pages statiques va du gratuit au très économique. Dans le cas d’un blog, il n’y a pas vraiment de justification de servir les pages de manière dynamique si ce n’est le côté pratique pour la maintenance.
Comment publier un site WordPress sous forme de pages statiques
Après avoir cherché sur Internet les solutions possibles, j’en suis arrivé à la conclusion que la solution la plus simple était la plus évidente: utiliser HTTrack pour copier le site et apporter quelques ajustements mineurs sur le résultat de la copie. Il existe plusieurs extensions WordPress pour faire ça mais différentes raisons me laissent penser que ce n’est pas une solution très sécurisante, et ce n’est pas spécialement économique non plus. Il y avait aussi l’option d’utiliser une autre solution que WordPress comme backend, tel que Jekyll, mais j’ai suffisament investi de temps sur WordPress pour préférer capitaliser dessus.
Depuis la migration, le principe est le suivant:
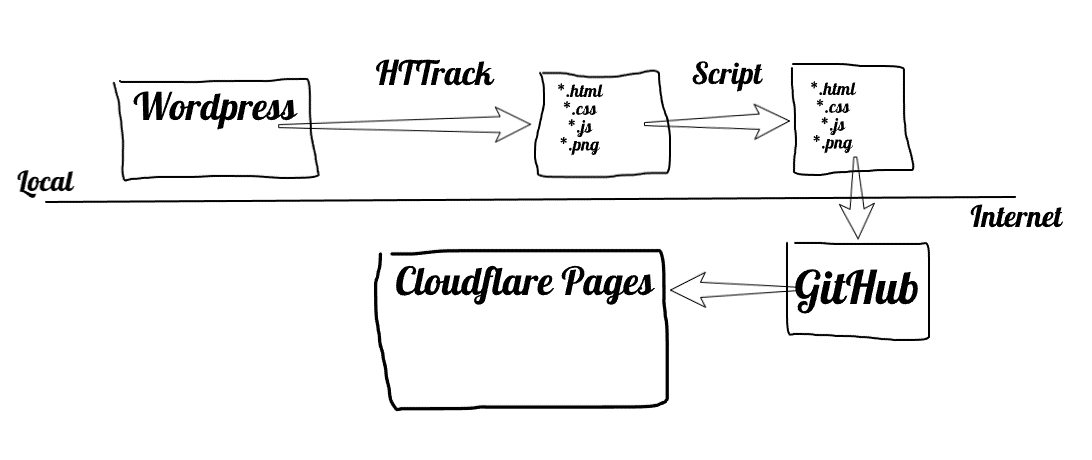
Étape 1: créer son instance WordPress locale
Evidemment, on peut déployer WordPress en local de manière beaucoup plus simple sans Kubernetes.
Comme j’avais déjà un cluster Kubernetes local, j’ai suivi ce tutoriel que j’ai adapté à la marge:
Example: Deploying WordPress and MySQL with Persistent Volumes
Étape 2: Copie des données de l’ancien site WordPress
En gros, il faut copier tous les fichiers (typiquement par FTP ou autre solution similaire suivant l’hébergeur), et effectuer un export de la base de données MySQL (typiquement via PhpMyAdmin). Parmi les fichiers, le plus important dans mon cas était le contenu du répertoires « uploads » (images) et « themes » dans le répertoire « wp-content ».
Étape 3: Import des données sur le nouveau site WordPress
Je ne détaille pas toutes ces étapes car c’est décrit en long et en large sur beaucoup d’autres sites.
Pour la base MySql, il faut l’étape inverse: importer le script SQL qui a été exporté. Dans mon cas, j’ai ensuite dû modifier l’URL du site dans la table « wp_options ». Je suis resté sur une URL en http car je n’ai pas réussi à utiliser mon reverse proxy nginx sur lequel je déploie mes certificats TLS. Il me semble que WordPress gère assez mal les entêtes X-Forwarded- qui sont pourtant devenu un standard de-facto. Ce n’est pas bien grave pour une instance qui n’est pas exposée sur Internet.
Pour l’import des fichiers (notamment les images et le thème), sur Kubernetes c’est une partie un peu moins pratique: il faut identifier le nom du pod de WordPress et utiliser la commande kubectl cp. Par exemple kubectl cp dossier pod_wordpress:/a/b copiera le dossier nommé « dossier » (dans le répertoire de travail) dans le pod nommé « pod_wordpress » dans son chemin « /a/b » (le chemin final du dossier sera donc « /a/b/dossier » dans le conteneur).
Pour savoir où copier les fichiers dans le conteneur, le plus simple est de naviguer dans le répertoire « /var/www/html » avec un shell à l’intérieur du pod de WordPress (kubectl exec --stdin --tty pod_wordpress -- /bin/bash).
Une fois fait, tester en se connectant à l’instance locale pour vérifier que tout est là. En cas d’erreur de redirection sur la page d’authentification (après l’authentification), essayer de rafraichir la page de base du site. Ce serait un problème mineur de réglage d’URL ou de cookie.
Étape 4: Copie du site avec HTTrack
Là non plus je ne vais pas faire un tutoriel détaillé. Dans mon cas, la seule option que j’ai préféré modifier se trouve dans l’onglet « Expert Options », pour conserver les URLs originales dans les pages copiées. Cela rend plus simple le traitement avec le script de l’étape suivante.
A la fin de la copie, bien vérifier les erreurs rencontrées par HTTrack, et ajuster au besoin pour recommencer la copie. Il peut par exemple y avoir des liens cassés sur les images, il faut dans ce cas mettre à jour le site WordPress.
Étape 5: Script d’ajustements mineurs
Le rôle du script est d’adapter ce qui doit l’être avant de publier le site sous forme statique. Je pense que les besoins d’un tel script vont varier d’un site WordPress à un autre, c’est pourquoi je ne pense pas qu’il puisse y avoir une solution fiable à publier, prête à l’emploi. Étant le plus à l’aise avec c#, j’ai utilisé LinqPad pour aller vite.
Voici un résumé de ce script:
- Copie tous les fichiers *.html, *.css, et images du dossier de la copie HTTrack vers un dossier distinct (ne pas modifier les fichiers source facilite la répétition de l’exercice si on doit faire des ajustements). Dans mon cas je n’héberge aucun javascript. La structure des répertoires est répliquée. Le contenu du répertoire cible est d’abord effacé. Selon les liens découverts par HTTrack, il peut y avoir des ajustements mineurs, notamment en cas de mélange entre des URLs du site local et des URLs absolues de l’ancien site à migrer.
- HTTrack peut modifier le nom de certains fichiers (dans mon cas, il a modifié le nom de deux fichiers CSS, il faut donc les copier avec le nom original avant modification par HTTrack.
- Les fichiers HTML sont légèrement transformés par HTTrack, le script retire ces ajouts grâce à des expressions régulières assez basiques. De plus on veut modifier les URLs (soit du site WordPress local, soit des URLs absolues de l’ancien site à migrer) pour les remplacer par la nouvelle URL publique.
Étape 6: Publication des fichiers sur un dépôt GitHub
Rien de particulier, c’est une simple copie du répertoire copié par le script, à publier dans un dépôt git.
Si, une chose particulière: le fichier _headers à placer à la racine du site (à côté du fichier « index.html » dans le dépôt git), avec ce contenu comme bon point de départ:
/feed/*
Content-Type: application/rss+xml; charset=UTF-8
X-Robots-Tag: noindex
https://:project.pages.dev/*
X-Robots-Tag: noindex
Celui-ci indique à Cloudflare Pages de retourner l’entête HTTP « Content-Type: application/rss+xml; charset=UTF-8 » pour l’URL /feed, et demande aux robots de ne pas indexer ni le feed, ni les pages « preview ». Avoir un site statique n’empêche pas d’avoir un flux RSS.
Étape 7: Intégration du dépôt GitHub à Cloudflare Pages
C’est une étape très simple, d’autant plus si le nom de domaine personnalisé du site était déjà géré par les DNS de Cloudflare. Suivre la documentation sur Cloudflare Pages. Je conseille de bien lire leur documentation (c’est rapide, il n’y a en fait pas grand chose, ça reste un site statique). Par exemple il me semble utile de connaître la limitation du nombre de synchronisations gratuites entre GitHub et Cloudflare Page: 500 par mois.
Une fois terminé (cela ne prend que quelques minutes), le site est accessible et son contenu devrait être la copie du site WordPress.
Si le site WordPress est modifié, il suffit de répéter les étapes 4 à 6. Si tout se passe bien, c’est très rapide. Bien contrôler le log d’erreurs de HTTrack pour vérifier que tout se passe bien (HTTrack peut créer des images corrompues si le serveur retourne une page d’erreur à la place, telle que HTTP 404). Cela m’est arrivé, c’est d’ailleurs pour ça que certaines images du blog ont une URL n’ayant pas la même date que les articles car j’ai dû les retrouver et les redéposer sur WordPress (l’URL n’est malheureusement pas quelque chose de configurable sans plugin).
Un avantage dont j’ai pris conscience par hasard avec HTTrack est qu’on identifie rapidement les liens cassés grâce à cette copie, chose que l’on ne pense pas à contrôler sinon, faute d’outil pratique pour ça (il existe surement des plugins WordPress pour ça aussi).
Avec un peu de temps, ce n’est probablement pas difficile à automatiser: HTTrack peut être lancé dans un conteneur docker (image disponible en cherchant), il suffirait donc sans doute de le lancer directement depuis Kubernetes par un programme capable de détecter les mises à jour du site (grâce au feed RSS de WordPress) d’exécuter le script sur le résultat de la copie, et enfin publier le tout via une Pull Request sur GitHub.