
Alertmanager est principalement conçu pour être déclenché par Prometheus. On peut également déclencher (et résorber) des alertes à partir d’un client HTTP via l’API.
Cela m’a donné l’idée d’adapter LocalSmtpRelay, un petit programme que j’ai réalisé il y a 3 ans, par lequel passent toutes les notifications par email de mon réseau local. Ces notifications viennent typiquement de mon NAS ou de mon pare-feu pfSense par exemple, et plus généralement de n’importe quel service déployé qui émet des emails (tel qu’Alertmanager lui-même). L’idée est de rediriger certaines notifications email vers l’API d’Alertmanager, et ainsi de bénéficier de sa fonction principale qu’est le throttling des alertes: la même « alerte » peut se déclencher des dizaines de fois, très peu d’emails seront envoyés. Dans la continuité de ce travail, j’ai dû intégrer un petit serveur LLM (basé sur Llma.cpp) afin de déduire une description courte et intelligible à partir du contenu des notifications parfois verbeux et technique.
Dans la grande majorité des cas, les notifications simples par email fonctionnent comme attendu. Cependant il arrive que quelques notifications soient agaçantes par moment. C’est là qu’Alertmanager a tout son rôle. J’ai par exemple plusieurs connexions de clients VPN sur pfSense, avec une notification lorsque la connexion est perdue ou restaurée. Lorsque la connexion est instable, je peux ainsi recevoir des notifications de manière répétée (cela peut être par dizaines, voire centaines pendant plusieurs heures). En règle générale, une perte de connexion sur un client VPN n’a rien de critique car le pare-feu dispose de plusieurs connexions et il faudrait que toutes soient instables en même temps, ce qui est très rare. Et quand bien même toutes les connexions étaient perdues, certes ma connexion internet serait impactée (puisque l’essentiel de mon trafic passe par ces connexions VPN, sauf exceptions), je ne souhaite pas pour autant recevoir d’innombrables alertes la nuit, ou même la journée si je ne suis pas chez moi.
Mon premier réflexe a été de trouver le moyen d’intégrer les métriques de pfSense à Prometheus, pour ensuite configurer des alertes basées sur ces métriques. Je n’ai cependant rien trouvé qui publie le statut des gateways. Il est bien possible de remonter quelques métriques par SNMP, mais, d’abord c’est super compliqué, et une fois qu’on réussi, on se rend compte que très peu de métriques sont publiées par ce canal. Il est plus simple d’installer le package Node Exporter pour pfSense, qui remonte davantage de données, mais pas le statut des gateways.
Ma seconde piste a été ce petit projet qui expose, via un script PHP sans authentification, le statut des gateways dans un format JSON. Cependant la réponse n’est pas directement exploitable par Prometheus. Il aurait fallu que je l’adapte, et je ne suis pas du tout spécialiste de PHP, cela m’aurait donc sûrement pris un certain temps et peu de plaisir. J’aurai peut-être aussi pu utiliser Prometheus Blackbox Exporter avec la configuration adéquate (ce serait en théorie possible grâce aux expressions régulières pour valider la réponse HTTP, mais je n’ai pas creusé cette piste).
Au final, grâce à l’API d’Alertmanager très simple à utiliser, adapter LocalSmtpRelay m’a semblé être la solution la plus simple qui pourrait être réutilisée dans d’autres cas similaires, où seule l’alerte email m’intéresse, et pas l’historique des métriques.
Fonctionnement des Alertes
Voici à quoi ressemble un email envoyé par pfSense lors d’un incident sur une gateway (avec un sujet générique pour toutes les notifications):
Notifications in this message: 2
================================
22:55:21 MONITOR: VPN1_WAN has packet loss, omitting from routing group VPN_WAN_Group
1.0.0.1|10.24.162.167|VPN1_WAN|17.101ms|0.819ms|23%|down|highloss
22:55:21 MONITOR: VPN2_WAN has packet loss, omitting from routing group VPN_WAN_Group
1.0.0.3|10.34.98.68|VPN2_WAN|18.314ms|3.575ms|22%|down|highloss
Ou bien lorsque la connexion semble rétablie:
Notifications in this message: 1
================================
10:56:50 MONITOR: VPN2_WAN is available now, adding to routing group VPN_WAN_Group
1.0.0.3|10.34.114.242|VPN2_WAN|66.727ms|40.33ms|14%|online|loss
Et ces notifications peuvent faire ping-pong pendant plusieurs heures.
Pour envoyer cela sous forme d’alerte à Alertmanager, ce serait quelque chose comme:
HTTP POST http://alertmanager:9093/api/v2/alerts
[
{
"labels": {
"alertname": "pfsense-routing-gateway",
"severity": "warning"
},
"annotations": {
"summary": "Routing gateway has packet loss",
"description": "Notifications in this message: 1
================================
10:56:50 MONITOR: VPN2_WAN is available now, adding to routing group VPN_WAN_Group
1.0.0.3|10.34.114.242|VPN2_WAN|66.727ms|40.33ms|14%|online|loss"
}
}
]
Le seul champ obligatoire d’une alerte est le label alertname, cependant les champs conventionnels sont le label severity et les annotations summary et description. Les labels sont utilisés comme tags (ils apparaitront dans le sujet de l’email envoyé par Alertmanager) tandis que les annotations sont traitées comme du texte rendu dans le corps de l’email. Le champ « summary » est une description courte de l’alerte, le champ « description » est une description éventuellement plus détaillée et verbeuse.
Le template par défaut de l’email envoyé par Alertmanager ressemble à cela:
|
Déclencher et résorber une alerte
Alertmanager a les concepts de « Firing alert » et « Resolved alert ». Une alerte résorbée (ou résolue) est une alerte qui est terminée. Pour envoyer une alerte terminée, il suffit de définir le champ optionnel « endsAt » à une valeur passée.
Dans le cas de pfSense qui envoie une notification en cas d’incident et de résolution d’incident, l’idée est de reconnaître chaque cas à partir d’une expression régulière, et selon le cas d’envoyer une alerte avec un champs « endsAt » de plusieurs heures dans le futur (par exemple 4 heures), ou bien avec une valeur passée.
Evidemment, ce n’est pas parfait: une notification de pfSense peut contenir à la fois un incident (une connexion VPN temporairement exclue du routage WAN) et un incident résolu (une autre connexion VPN réintégrée au routage WAN). A l’usage, ça fonctionne cependant plutôt bien, il faut juste savoir que le mapping entre notification et alerte n’est pas absolument parfait.
Déduire une description à partir du texte de la notification grâce à un LLM
Le contenu du message de pfSense peut contenir plusieurs notifications et celles-ci ne sont pas spécialement très lisibles.
Je ne suis pas spécialement fan de la hype autour des LLM, mais c’est une tâche qui semble destinée à cet outil. Mon idée a donc été de déployer un serveur LLM dans mon réseau (je n’ai pas envie d’envoyer mes données, quelles qu’elles soient, sur Internet).
La solution open source Llma.cpp fait plutôt bien le job et est très facile à déployer via Docker ou Kubernetes.
Déploiement du serveur llama.cpp sur Kubernetes
En m’appuyant sur leur documentation pour Docker, j’en ai déduit ces manifestes pour Kubernetes:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: llama-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 5Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: llama-deployment
labels:
app: llama
spec:
selector:
matchLabels:
app: llama
template:
metadata:
labels:
app: llama
spec:
securityContext:
fsGroup: 2000
volumes:
- name: llama-model
persistentVolumeClaim:
claimName: llama-pvc
initContainers:
- name: permission-fix
image: busybox
command: ['sh', '-c']
args: ['chown -R root:2000 /models']
volumeMounts:
- name: llama-model
mountPath: "/models"
- name: init-curl-download-model
image: quay.io/curl/curl
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 1001
runAsGroup: 2000
args: ["-o", "/models/Llama-3.2-3B-Instruct-Q4_K_M.gguf", "-v", "--skip-existing", "-L", "https://huggingface.co/unsloth/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q4_K_M.gguf?download=true"]
volumeMounts:
- name: llama-model
mountPath: "/models"
containers:
- name: llama
imagePullPolicy: IfNotPresent
image: ghcr.io/ggerganov/llama.cpp:server
startupProbe:
httpGet:
path: /metrics
port: 8080
failureThreshold: 360
periodSeconds: 10
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /metrics
port: 8080
failureThreshold: 60
periodSeconds: 60
timeoutSeconds: 10
readinessProbe:
httpGet:
path: /metrics
port: 8080
periodSeconds: 60
timeoutSeconds: 10
securityContext:
runAsUser: 1001
runAsGroup: 2000
resources:
limits:
cpu: "1"
memory: "4Gi"
# Cf https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
args: ["-m", "/models/Llama-3.2-3B-Instruct-Q4_K_M.gguf", "--no-warmup", "-c", "4096", "-np", "2", "-dt", "0.1", "--metrics"]
ports:
- containerPort: 8080
volumeMounts:
- name: llama-model
mountPath: "/models"
---
apiVersion: v1
kind: Service
metadata:
name: llama-service
labels:
app: llama
spec:
type: ClusterIP
selector:
app: llama
ports:
- port: 8080
protocol: TCP
targetPort: 8080
name: http
Ce déploiement va télécharger le modèle Llama 3.2 3B Instruct, en version 4-bit, adapté à un petit serveur (requiert 4 Go de RAM). Ce n’est pas le plus impressionnant mais il suffit pour mon usage.
L’un des paramètres les plus importants je pense dans le manifeste est la limitation des ressources en CPU et RAM (j’ai plafonné à 1 coeur CPU et 4Go de RAM), car une mauvaise configuration (par exemple avec un modèle plus évolué et donc plus consommateur) peut mettre à genoux un petit cluster Kubernetes jusqu’à rendre la machine quasiment indisponible.
La ligne de commande inclut l’API de métriques compatible Prometheus, ce qui permet de suivre l’usage réel en créant son dashboard dans Grafana. Les métriques sont assez basiques, en gros le temps de calcul consommé, notamment sur l’interprétation du prompt et la génération de la réponse (et le débit en tokens par seconde).
Le serveur offre même une UI basique pour le tester directement.
L’API du serveur a une compatibilité avec l’API d’OpenAi, on peut donc l’utiliser en théorie à partir d’un client qui supporte OpenAi pour autant que l’URL soit configurable.
Premiers résultats
Le prompt est configurable. Par défaut, LocalSmtpRelay va utiliser celui-ci:
System:
You respond directly to user's instructions.
Your responses are always made of a single short
sentence of less than 250 characters, without
introductory text, without any text formatting.
Do not add any note at the end of your response.
User:
### Instruction:
Identify up to 2 main sentences in following content
and summarize them in a single sentence:
Notifications in this message: 2
================================
22:55:21 MONITOR: VPN1_WAN has packet loss, omitting from routing group VPN_WAN_Group
1.0.0.1|10.24.162.167|VPN1_WAN|17.101ms|0.819ms|23%|down|highloss
22:55:21 MONITOR: VPN2_WAN has packet loss, omitting from routing group VPN_WAN_Group
1.0.0.3|10.34.98.68|VPN2_WAN|18.314ms|3.575ms|22%|down|highloss
### Response:
Le résultat, après un peu de patience, est:
Two VPN connections are experiencing packet loss and are
omitting from routing group VPN_WAN_Group.
Sur mon petit serveur, le débit est de 8 tokens par seconde pour le prompt et 2 tokens prédits par seconde pour le résultat. Selon l’état du cache, ce type de demande prend entre 11 et 45 secondes! Sur mon ordinateur de bureau, la même demande prend autour de 5 secondes grâce au GPU de ma carte graphique (testé grâce à gpt4all avec le même modèle et des paramètres similaires).
J’ai également testé le modèle plus petit Llama 3.2 1B Instruct, le résultat est plus décevant. Je pense que le modèle 3B est actuellement le minimum viable pour un usage généraliste et qui respecte à peu près les instructions qu’on lui donne.
Le résultat final de l’email envoyé par Alertmanager, avec description via le LLM, ressemble à:
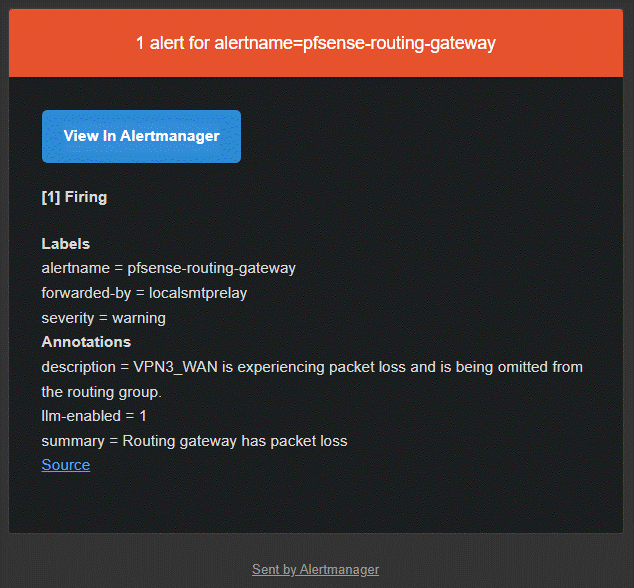
Au final, j’ai même ajouté une configuration à LocalSmtpRelay pour modifier le sujet de certains emails avec le résultat du LLM (sans la partie Alertmanager). C’est utile pour certaines notifications de mon NAS: comme l’envoi par email est un mécanisme générique quel que soit le service sous-jacent, toutes les notifications ont le même sujet générique. LLM permet d’appliquer un sujet plus spécifique qui permet de savoir de quoi il s’agit sans avoir à lire le contenu du message.
Le projet LocalSmtpRelay est disponible sur GitHub, toute la configuration y est documentée.