
Dans un précédent article, j’abordais l’utilisation de l’API d’Alertmanager pour convertir une notification par email en alerte (pouvant aussi être notifiée par email). Cet article est à la fois un retour d’expérience et la suite du premier article, avec une nouvelle amélioration de LocalSmtpRelay.
La gestion d’alertes via l’API d’Alertmanager s’est montrée efficace partiellement. Une alerte a deux états: « Firing » et « Resolved ». Si de nombreux emails sont routés vers le même état d’alerte (par exemple « Firing », « Firing », « Firing », etc.), Alertmanager remplit son rôle de throttling en réduisant le nombre de notifications par email issues de cette alerte (et en répétant périodiquement l’alerte tant qu’elle n’est pas résolue). C’est contrôlé via ses paramètres group_by, group_wait, group_for, group_interval, repeat_interval. En revanche, en cas de « flapping », c’est-à-dire si la source envoie des alertes qui changent d’état de manière rapide et répétée (par exemple « Firing », « Resolved », « Firing », « Resolved », etc.), dans ce cas le « flapping detection » n’est pas prévu pour être géré par Alertmanager mais par Prometheus (ce que je trouve contre-intuitif). En effet, ce serait le paramètre keep_firing_for de Prometheus (et non d’Alertmanager malheureusement) qu’il faudrait utiliser, pour lui indiquer de considérer un temps de latence avant de résoudre une alerte, même si la condition de l’alerte n’est plus remplie temporairement.
La solution, pour s’appuyer sur Alertmanager, est donc de passer par Prometheus, et donc de convertir les notifications par email en métriques que Prometheus peut collecter, et sur lesquelles ont peut s’appuyer pour configurer des règles d’alertes. Concrètement, cela signifie exposer un endpoint HTTP /metrics depuis le service LocalSmtpRelay, avec des métriques dédiées à certaines notifications email que l’on reconnaît via des expressions régulières (une pour « Firing » qu’on traduit par l’état 1 sur sa métrique correspondante, une autre pour « Resolved », qu’on traduit par l’état 0 sur la même métrique).
C’est ce que j’ai fait et ça marche plutôt très bien. Voici le concept en schéma:
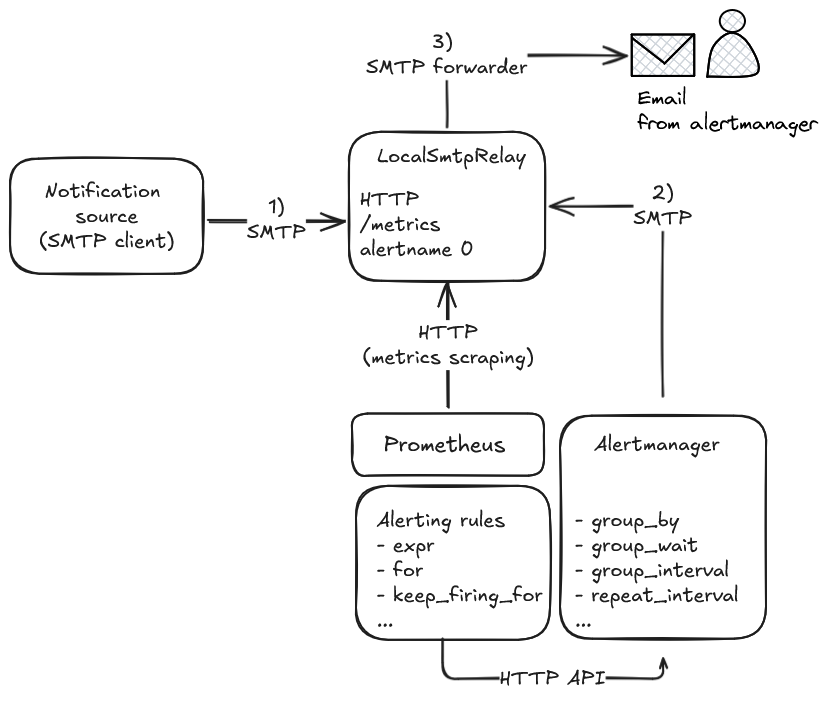
Côté configuration, il n’y a rien à changer du côté d’Alertmanager (s’il est déjà correctement configuré). Il faut surtout ajouter une target dans Prometheus pour collecter le nouvel endpoint /metrics de LocalSmtpRelay, puis il faut configurer des « alerting rules ».
Pour la nouvelle target, c’est à ajouter dans le fichier de configuration principal de Prometheus (sur mon installation, il s’agit de « /etc/prometheus/prometheus.yml »):
scrape_configs:
- job_name: 'localsmtprelay'
scrape_interval: 20s
static_configs:
- targets: ["localsmtprelay.my-domain"]
scheme: https
metrics_path: /metrics
Pour les alerting rules, c’est typiquement un fichier à part (sur mon installation, il s’agit de « /etc/prometheus/alerts/localsmtprelay.yml »):
groups:
- name: pfsense_routing_gateway
rules:
- alert: pfSense-routing-gateway-down
expr: pfsense_routing_gateway_down{job="localsmtprelay"} == 1 and localsmtprelay_up{job="localsmtprelay"} != 0
for: 10m
keep_firing_for: 60m
labels:
severity: warning
annotations:
summary: "Routing gateway has packet loss"
- alert: LocalSmtpRelay-Missing-Data
expr: absent(localsmtprelay_up{job="localsmtprelay"}) == 1
labels:
severity: warning
annotations:
summary: "Missing LocalSmtpRelay metric"
description: "Notification messages sent to LocalSmtpRelay will not be monitored by Prometheus and Alertmanager."
On peut noter qu’il y a deux règles (deux alertes) définies: « pfSense-routing-gateway-down » correspond à mon exemple d’alerte via une notification de pfSense (un pare-feu). « LocalSmtpRelay-Missing-Data » est une alerte activée si Prometheus ne peut plus collecter les métriques de LocalSmtpRelay. En effet, comme la source de l’alerte et sa résolution est LocalSmtpRelay, si celui-ci n’est plus opérationnel du point de vue de Prometheus, il ne faut plus que les alertes qui en dépendent soit activées.
Enfin, la configuration de LocalSmtpRelay (supporté à partir de la version 1.3.3) où j’ai ajouté cette nouvelle section:
"MetricConverter": {
"MessageRules": [
{
"MetricName": "pfsense_routing_gateway_down",
"Description": "Set to 1 when receiving a notification from pfsense for routing gateway removed from routing group, and 0 when resolution notification is received or after some time",
"RegexOnField": "Body",
"ActivationRegex": "omitting from routing group",
"ResolutionRegex": "adding to routing group",
"ResolutionTimeout": "30.00:00:00"
}
]
},
Si tout va bien, le endpoint /metrics de LocalSmtpRelay retournera quelque chose comme ça:
# HELP localsmtprelay_up Service is running (always 1 while metrics endpoint is reachable)
# TYPE localsmtprelay_up gauge
localsmtprelay_up 1
# HELP smtp_forwarder_up SMTP client is up
# TYPE smtp_forwarder_up gauge
smtp_forwarder_up 1
# HELP smtp_forwarder_connected SMTP client is currently connected
# TYPE smtp_forwarder_connected gauge
smtp_forwarder_connected 0
# HELP pfsense_routing_gateway_down Set to 1 when receiving a notification from pfsense for routing gateway removed from routing group, and 0 when resolution notification is received or after some time
# TYPE pfsense_routing_gateway_down gauge
On pourra noter que la métrique « pfsense_routing_gateway_down » de notre example n’est pas publiée: elle le sera seulement lorsqu’un message de notification sera reconnu comme activant l’alerte.