
Surveiller de nombreuses applications déployées dans Kubernetes peut devenir fastidieux si on ne centralise pas la télémétrie de manière unifiée.
Pour le rendre plus digeste, j’ai divisé cet article en deux parties:
- Partie 1 (cet article): OpenTelemetry Collector pour collecter les logs de tous les containers de manière générique, et de métriques système.
- Partie 2: présentation de OTTL et des stanza operators pour une configuration avancée d’OpenTelemetry Collector qui améliore le parsing des logs.
Si une introduction à OpenTelemetry est nécessaire, je suggère cette entrée en matière.
Dans cette première partie, je présente une utilisation du helm chart OpenTelemetry Collector ainsi que d’un déploiement plus classique du même collecteur (sans operator Kubernetes, sans helm chart), dans le cadre d’un usage précis (donc pas forcément adapté à tous les cas), et principalement tourné sur la collecte des logs des containers du cluster Kubernetes:
- Avec le helm chart Signoz: déployer un backend (réceptacle final) pour la télémétrie: fourni une vue unifiée des logs, traces et métriques.
- Grâce au helm chart OpenTelemetry Collector: déployer deux instances de
collecteur dédié au cluster K8s
- Un collecteur en mode
daemonsetpour collecter de manière générique (avec une seule configuration) les logs de tous les containers, et leurs principales métriques système (vues par Kubernetes, c’est-à-dire CPU, mémoire, etc.), ainsi que les métriques du serveur hôte. Les logs sont collectés de manière générique grâce au File Log Receiver qui parse les fichiers contenant la sortie console (STDOUT et STDERR) des containers. Un inconvénient de ce parsing générique est que l’on ne supporte pas les logs sur plusieurs lignes (notamment les erreurs avec stacktrace), ni la sévérité (en résumé les logs ne sont pas structurés). Mais au moins, on les centralise en une seule vue avec de nombreux filtres (par exemple par nom de container ou par nom de namespace).
C’est un peu « la méthode du pauvre » car on collecte avec peu d’efforts beaucoup de données, mais l’approche est imparfaite si on la compare à une intégration d’OpenTelemetry au niveau de chaque applicatif (qui demande davantage d’efforts). - Un collecteur en mode
deploymentpour collecter les métriques du cluster K8s ainsi que leseventsKubernetes (qui seront traduits en logs).
- Un collecteur en mode
- Avec un déploiement classique (sans helm) de type StatefulSet: déployer une instance d’OpenTelemetry Collector qui jouera le rôle de middleware afin d’ajouter une couche de persistance avant de rediriger la télémétrie vers le backend final (Signoz).
- Le tout au sein d’un cluster K8s d’un seul noeud dans le contexte d’un homelab. Rien n’empêche d’adapter pour un cluster de plusieurs noeuds, mais probablement pas à l’identique de ce qui est présenté.
Installer un backend OpenTelemetry: Signoz
Signoz est un outil open source de centralisation de la télémétrie, nativement compatible avec le protocole OpenTelemetry. Il permet donc de collecter et exploiter les logs, traces (distribuées) et métriques. Il existe des alternatives telles que Uptrace, OpenObserve… Signoz n’est pas spécialement une recommandation parmi les trois mais il est facile à déployer grâce à son helm chart, et fonctionnel, donc idéal pour l’illustration dans cet article.
L’installation au sein d’un cluster Kubernetes est documentée ici (avec le helm chart ici).
Concrètement, l’installation via helm se fait ainsi:
helm repo add signoz https://charts.signoz.io
kubectl create namespace signoz
helm install -n signoz --create-namespace signoz signoz/signoz
Le déploiement prend quelques minutes, on peut surveiller avec K9s ou un outil
similaire pour attendre que tout soit prêt.
On pourra voir que le chart a déployé 3
PVCs
: un pour
zookeeper (composant interne utilisé par signoz), un pour les données stockées
dans Clickhouse (pour les données de télémtrie), et un pour la base SQLite de
signoz (contient des données de configuration).
Par défaut, aucun service n’est exposé en dehors du cluster. Avec traefik, on peut ajouter un IngressRoute vers le port 8080 du service « signoz ». Sinon on peut ajouter un service de type NodePort que je ne documente pas ici.
Une fois le portail accessible, il faut créer le compte administrateur lors du premier accès à l’interface web.
Identifier l’instance OpenTelemetry Collector de Signoz
Signoz a déployé son propre OpenTelemetry Collector, vers lequel on va exporter la télémétrie du cluster Kubernetes. Pour l’identifier:
❯kubectl get services -n signoz
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
chi-signoz-clickhouse-cluster-0-0 ClusterIP None 9000/TCP,8123/TCP,9009/TCP 15m
signoz ClusterIP 10.43.124.210 8080/TCP,8085/TCP,4320/TCP 16m
signoz-clickhouse ClusterIP 10.43.225.252 8123/TCP,9000/TCP 15m
signoz-clickhouse-operator-metrics ClusterIP 10.43.194.1 8888/TCP 16m
signoz-otel-collector ClusterIP 10.43.126.37 14250/TCP,14268/TCP,8081/TCP,8082/TCP,8888/TCP,4317/TCP,4318/TCP 16m
signoz-zookeeper ClusterIP 10.43.28.118 2181/TCP,2888/TCP,3888/TCP 16m
signoz-zookeeper-headless ClusterIP None 2181/TCP,2888/TCP,3888/TCP 16m
signoz-zookeeper-metrics ClusterIP 10.43.61.243 9141/TCP 16m
L’URL vers laquelle on devra exporter sera donc
http://signoz-otel-collector.signoz:4317 pour OpenTelemetry Protocol en gRPC
et http://signoz-otel-collector.signoz:4318 pour OpenTelemetry Protocol en
HTTP.
Collecter tous les logs
Je suis parti de ce guide d’OpenTelemetry que je ne vais pas répéter ici.
L’important est de voir qu’il y a plusieurs helm charts proposés, avec plusieurs modes de déploiement proposés. Pour cette première étape, on veut déployer le helm chart « opentelemetry-collector » en mode « daemonset ». Ce mode s’assure de déployer une instance par noeud (donc une seule instance pour un cluster d’un seul noeud). Celui-ci va collecter les logs de tous les containers, et leurs principales métriques système, ainsi que les métriques du serveur hôte.
Voici la configuration appliquée via le fichier « values.yaml » du helm chart (documentation de ce helm chart ici):
mode: daemonset
image:
repository: otel/opentelemetry-collector-k8s
tag: "0.149.0"
# https://opentelemetry.io/docs/platforms/kubernetes/helm/collector/#cluster-metrics-preset
presets:
# enables the k8sattributesprocessor and adds it to the traces, metrics, and logs pipelines
kubernetesAttributes:
enabled: true
# enables the kubeletstatsreceiver and adds it to the metrics pipelines
kubeletMetrics:
enabled: true
hostMetrics:
enabled: true
# Enables the filelogreceiver and adds it to the logs pipelines
# Warning: https://github.com/open-telemetry/opentelemetry-helm-charts/tree/main/charts/opentelemetry-collector#warning-warning-risk-of-looping-the-exported-logs-back-into-the-receiver-causing-log-explosion
logsCollection:
enabled: true
config:
receivers:
jaeger: null
zipkin: null
filelog:
# Note receivers/filelog may consume significant cpu: https://github.com/open-telemetry/opentelemetry-collector-contrib/issues/27404
# More configuration described here: https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/filelogreceiver
poll_interval: 3s
max_concurrent_files: 10
exclude:
- /var/log/pods/otelcol-k8s_otel-collector-k8s-daemonset-opentelemetry-collector*_*/opentelemetry-collector/*.log
# Exclude Signoz (OTEL backend) to avoid logs collection loop
# Same for traefik (browsing signoz may emit logs in traefik depending on its configuration)
- /var/log/pods/signoz_*/*/*.log
- /var/log/pods/kube-system_traefik-*/traefik/*.log
exporters:
otlp_grpc:
endpoint: "http://signoz-otel-collector.signoz:4317"
tls:
insecure: true
service:
pipelines:
traces:
exporters: [otlp_grpc]
receivers: [otlp]
metrics:
exporters: [otlp_grpc]
logs:
exporters: [otlp_grpc]
On notera divers ajustements par rapport à la configuration montrée en exemple dans le guide d’OpenTelemetry, notamment:
poll_intervaletmax_concurrent_filesavec des valeurs conservatrices de ressources. Par défaut, le File Log Receiver est assez aggressif pour parser le plus rapidement possible tous les logs. C’est sans doute adapté pour un cluster en production, mais ça l’est beaucoup moins pour un homelab avec peu de ressources.- Certains receivers sont désactivés (jaeger, zipkin).
- Le plus important: l’ajout de l’exporter
otlp_grpcpour router la télémétrie vers notre backend signoz. - Noter enfin le bloc
exclude: important pour éviter de créer une boucle entre la collecte de logs et les logs générés par le collecteur lui-même.
Une fois déployé et opérationnel, si on retourne dans l’interface de Signoz, on devrait trouver les logs de tous nos containers:
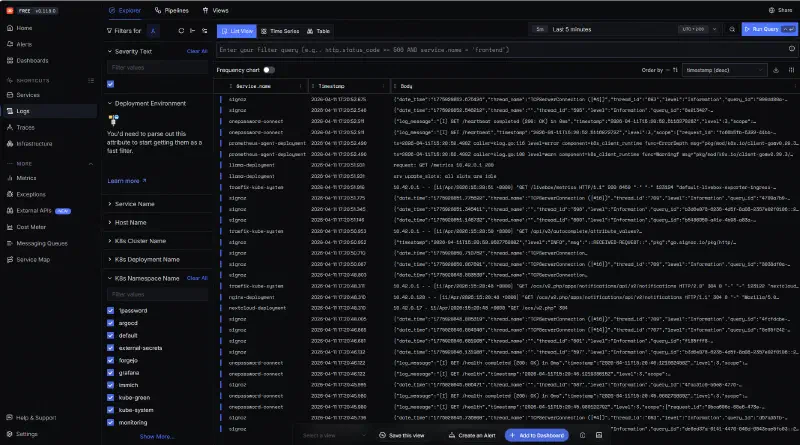
On peut ainsi retrouver tous nos logs, tous containers confondus. Si par exemple on s’intéresse au déploiement en cours d’une application via ArgoCD, on peut filtrer sur deux namespaces, « argocd » et celui de l’application déployée pour ne voir que ce qu’il se passe dans le contexte de ce déploiement.
En allant dans l’explorateur de métriques, on peut en trouver un certain nombre publiés par notre premier collecteur. Il est ainsi possible de créer des dashboards avec différents panneaux, sur le même principe que Grafana.
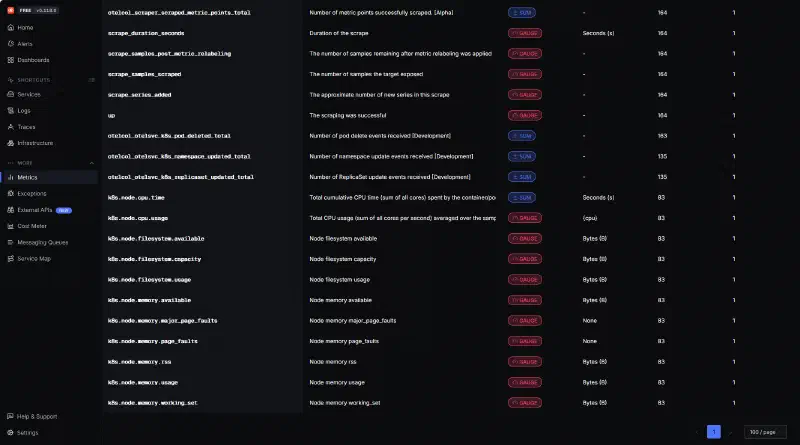
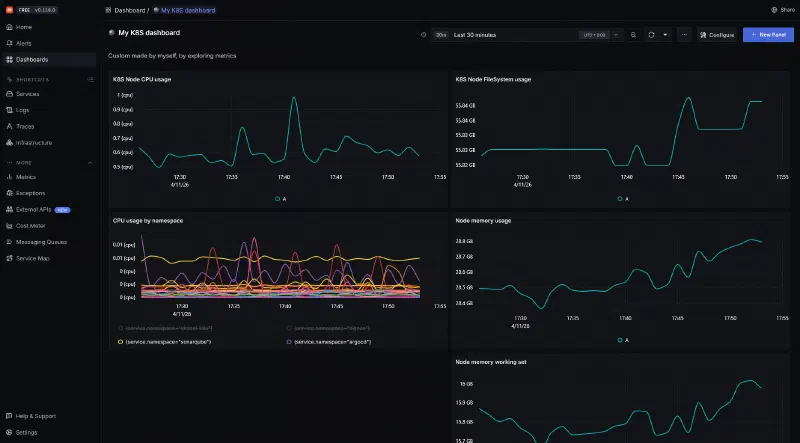
Limitations
Comme mentionné en début d’article, cette approche a une sérieuse limitation: il n’y a quasiment pas de structure. Les logs multi lignes (traces d’erreur notamment) ne sont pas bien géré (éclatés en autant de lignes de logs indépendantes). La sévérité (info, erreur…) n’est souvent pas bien reconnue (la Partie 2 permet d’améliorer cela). Parser des fichiers de logs de manière générique produit quelque chose d’un peu supérieur aux logs console, mais pas de beaucoup. En simplifiant grossièrement, la structure qui peut être ajoutée automatiquement post-parsing sont l’heure du log et les attributs du container (namespace, pod, container…). Si on s’intéresse à ce que fait File Log Receiver à partir des logs de containers dans Kubernetes, on pourra lire cet article de blog très intéressant (et si on veut encore creuser, voici l’issue GitHub originale).
L’avantage de cette technique est de faire ingérer à notre backend des logs d’un grand nombre de sources hétérogènes avec très peu d’effort.
L’approche la plus « propre » est d’intégrer OpenTelemetry directement au niveau de chaque application. Ainsi, les logs arrivent dans le backend nativement structurés depuis l’application source (pour autant que le SDK le permette, ce qui est le cas en .NET par exemple), les métriques peuvent être plus précises (pas seulement des métriques système, mais aussi les métriques fonctionnelles), les traces peuvent avoir une granularité bien supérieure (par exemple entre différentes méthodes ou au sein d’un bus in-process, ce que ne verrait pas une solution d’auto-instrumentation extérieure à l’application).
Collecter les Events Kubernetes
Pour les events, ainsi que des métriques supplémentaires, on déploiera une autre instance du même helm chart « opentelemetry-collector » configuré différemment, en mode « deployment ».
Voici la configuration appliquée via le fichier « values.yaml » du helm chart:
mode: deployment
image:
repository: otel/opentelemetry-collector-k8s
tag: "0.149.0"
# We only want one of these collectors - any more and we'd produce duplicate data
replicaCount: 1
# https://opentelemetry.io/docs/platforms/kubernetes/helm/collector/#cluster-metrics-preset
presets:
# enables the k8sclusterreceiver and adds it to the metrics pipelines
# https://opentelemetry.io/docs/platforms/kubernetes/collector/components/#kubernetes-cluster-receiver
clusterMetrics:
enabled: true
# enables the k8sobjectsreceiver to collect events only and adds it to the logs pipelines
# https://opentelemetry.io/docs/platforms/kubernetes/collector/components/#kubernetes-objects-receiver
kubernetesEvents:
enabled: true
config:
receivers:
k8s_cluster:
collection_interval: 30s
metadata_collection_interval: 10m
node_conditions_to_report:
[Ready, MemoryPressure, DiskPressure, PIDPressure, NetworkUnavailable]
allocatable_types_to_report: [cpu, memory, ephemeral-storage]
exporters:
otlp_grpc:
endpoint: "http://signoz-otel-collector.signoz:4317"
tls:
insecure: true
service:
pipelines:
traces:
exporters: [otlp_grpc]
metrics:
exporters: [otlp_grpc]
logs:
exporters: [otlp_grpc]
Une fois déployé et opérationnel, pour filtrer les events Kubernetes, on peut
utiliser ce type de recherche dans les logs: k8s.resource.name = 'events'. On
peut aussi filtrer en fonction des deux niveaux « Normal » et « Warning »
(exemple: body.object.type = 'Warning').
Persistance temporaire de la télémétrie (résilience)
La télémétrie qui arrive dans le backend (Signoz) est envoyée par les deux collecteurs configurés précédemment via le helm chart « opentelemetry-collector ». Si Signoz n’est pas opérationnel, ces collecteurs vont faire plusieurs tentatives d’envoi. Si aucune tentative ne réussit ou si le collecteur source est redémarré, les données de télémétrie non acheminées sont perdues.
OpenTelemetry Collector a le concept de file persistante: avec la configuration adéquate, les données sont d’abord écrites dans des fichiers, puis une file de traitement tente de les envoyer avant de supprimer la copie locale.
Pour que la configuration reste simple, je propose de déployer notre propre instance d’OpenTelemetry Collector, qui servira de middleware avec une couche de persistance avant de router la télémétrie vers le backend final. Une alternative aurait été de modifier la configuration des deux instances déployées via le helm chart « opentelemetry-collector ». Avoir une troisième instance plus centrale permet de ne gérer cet aspect qu’à un seul endroit. Cela pourra éventuellement être intéressant par la suite pour ajouter d’autres traitements dans une configuration centrale d’OpenTelemetry Collector. Cela est néanmoins plus fragile qu’ajouter la persistance dans chacune des instances de collecteur.
Voici les manifestes de notre nouveau collecteur (en mode StatefulSet):
apiVersion: v1
kind: Namespace
metadata:
name: otelcol
labels:
name: otelcol
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: otelcol-data
namespace: otelcol
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Service
metadata:
name: otelcol-service
namespace: otelcol
labels:
app.kubernetes.io/name: otelcol
spec:
type: ClusterIP
selector:
app.kubernetes.io/name: otelcol
ports:
- name: otel-http
port: 4318
protocol: TCP
targetPort: 4318
- name: otel-grpc
port: 4317
protocol: TCP
targetPort: 4317
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: otelcol
namespace: otelcol
labels:
app.kubernetes.io/name: otelcol
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: otelcol
template:
metadata:
labels:
app.kubernetes.io/name: otelcol
spec:
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: otelcol-data
- name: config-volume
configMap:
name: otelcol-config
containers:
- name: otelcol-contrib
# See https://github.com/open-telemetry/opentelemetry-collector-releases/releases
image: ghcr.io/open-telemetry/opentelemetry-collector-releases/opentelemetry-collector-contrib:0.150.1
ports:
- containerPort: 4317
- containerPort: 4318
volumeMounts:
- name: data-volume
mountPath: /var/lib/otelcol/file_storage
- name: config-volume
mountPath: /etc/otelcol-contrib/config.yaml
subPath: config.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: otelcol-config
namespace: otelcol
labels:
app.kubernetes.io/name: otelcol
data:
config.yaml: |
extensions:
# See https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/extension/storage/filestorage/README.md
file_storage/persistent_queue:
directory: /var/lib/otelcol/file_storage/queue
create_directory: true
# recreate: true - see https://github.com/open-telemetry/opentelemetry-collector-contrib/issues/35899
recreate: true
compaction:
directory: /var/lib/otelcol/file_storage/tmp/
on_rebound: true
cleanup_on_start: true
check_interval: 30s
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
memory_limiter:
check_interval: 3s
limit_percentage: 75
spike_limit_percentage: 15
exporters:
# See https://github.com/open-telemetry/opentelemetry-collector/blob/main/exporter/otlpexporter/README.md
otlp_grpc:
endpoint: "http://signoz-otel-collector.signoz:4317"
tls:
insecure: true
sending_queue:
enabled: true
num_consumers: 10
# queue_size is the max nb of batches that can be stored on disk. Need to adapt it to expected max outage to recover.
queue_size: 150000
storage: file_storage/persistent_queue
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 0
service:
extensions: [file_storage/persistent_queue]
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter]
exporters: [otlp_grpc]
metrics:
receivers: [otlp]
processors: [memory_limiter]
exporters: [otlp_grpc]
logs:
receivers: [otlp]
processors: [memory_limiter]
exporters: [otlp_grpc]
Une fois ce troisième collecteur déployé, il faut mettre à jour la configuration
des deux premiers afin de remplacer le endpoint Signoz par ce nouveau collecteur
intermédiaire: dans le fichier « values.yaml » de configuration des helm charts,
il faut remplacer « http://signoz-otel-collector.signoz:4317 » par
« http://otelcol-service.otelcol:4317 » (le fichier values.yaml peut être
ré-appliqué avec la commande
helm upgrade open-telemetry/opentelemetry-collector -f values.yaml).
Pour vérifier que la persistance fonctionne, on peut arrêter le collecteur du backend (Signoz en l’occurence) pendant suffisamment longtemps. Puis redémarrer le collecteur central (avec persistance) pour vérifier que les données sont bien persistées sur disque et non en mémoire. Enfin relancer le collecteur du backend pour s’assurer qu’on retrouve notamment nos logs de containers qui ont été publiés pendant que le backend n’était plus opérationnel.
Voici en gros les commandes à utiliser (si on utilise un outil comme ArgoCD, il faut s’assurer que la synchronisation n’est pas automatique, sinon ArgoCD va restaurer les containers qu’on éteint et fausser ce test):
# Arrêter le collecteur du backend:
kubectl scale --replicas=0 deployment/signoz-otel-collector -n signoz
# Attendre suffisamment longtemps pour
# simuler une indisponibilité du backend...
# Redémarrer le collecteur central avec la persistance sur fichiers:
kubectl scale --replicas=0 statefulset/otelcol -n otelcol
kubectl scale --replicas=1 statefulset/otelcol -n otelcol
# Relancer le collecteur du backend:
kubectl scale --replicas=1 deployment/signoz-otel-collector -n signoz
Si tout va bien, on retrouve les logs qui ont été publiés pendant que le backend était éteint.
Limitations
Cela permet d’améliorer la résilience du système même si ce n’est pas parfait.
En effet, selon le design du backend, des pertes sont quand même possible. Par
exemple Signoz est basé sur
plusieurs composants dont sa propre instance d’OpenTelemetry Collector qui route ses données vers Clickhouse.
Il est malheureusement possible que son collecteur accepte de recevoir des
données sans être en mesure de les acheminer à Clickhouse, par exemple pendant
une mise à jour qui se passe mal. Dans ce cas, même notre collecteur avec
persistance n’y pourra rien car de son point de vue, ses données ont bien été
acheminées à leur destination. Une solution spécifique à Signoz est de modifier
la configuration de son collecteur. Je ne détaille pas cette approche car
modifier une ressources interne de son déploiement géré par helm chart n’est pas
idéal. Cependant si on s’intéresse au sujet, il suffit remplacer le ConfigMap
nommé « signoz-otel-collector » dans son namespace (pour voir son contenu
actuel: kubectl get cm signoz-otel-collector -n signoz -o yaml). Cela reste un
élément élégant d’OpenTelemetry: on peut retrouver la même syntaxe de
configuration dans différents composants du système.
Et OpenTelemetry Operator alors ?
Le helm chart « opentelemetry-operator » permet aussi de déployer des instances de collecteur (plutôt que gérer soit-même le manifeste de type « StatefulSet » décrit juste avant), mais il sert surtout à configurer l’auto-instrumentation d’applications (c’est-à-dire injecter l’export vers notre collecteur OpenTelemetry sans modifier l’application).
La théorie est que ça supporte la plupart des langages tels que Go, .NET, Java, Node.js, Python. En pratique, j’ai trouvé ça assez fragile. Il y a quand même un peu de spécifique par application à appréhender, et dans plusieurs cas ça n’a juste pas fonctionné (sans erreurs, mais sans logs collectés), dans d’autres ça a carrément cassé l’application cible, dans très peu cela a bien fonctionné et je ne trouve pas que le résultat mitigé obtenu soit à la hauteur de l’effort dans un contexte de homelab.
Par exemple, un cas d’auto-instrumentation qui a bien fonctionné pour moi est l’application openHAB en Java. L’intérêt réside sur le parsing correct de la sévérité (facilitant le filtrage des logs par niveau) car les messages de cette application ne sont pas particulièrement structurés par ailleurs. J’ai également testé avec succès sur une de mes applications en .NET. Je pense que pour Java et .NET, c’est probablement très fonctionnel (mais avec un intérêt variable selon comment les logs sont implémentés par l’application). J’ai eu moins de succès sur des applications Python, Node.js et Go (ce dernier langage semble être le plus fragile à auto-instrumenter car il y a des restrictions de version et du paramétrage spécifique par application).
Pour aller plus loin…
Si on souhaite aller plus loin, on peut exploiter les instructions OTTL et les stanza operators d’OpenTelemetry Collector: c’est l’objet de la seconde partie dans cet autre article: OpenTelemetry Collector: OTTL et stanza operators à la rescousse d’un parsing imparfait.
Références
- OpenTelemetry: Observability primer (core observability concepts)
- OpenTelemetry Collector for Kubernetes: Getting Started (helm chart)
- Introducing the new container log parser for OpenTelemetry Collector
- GitHub opentelemetry-collector-contrib#31959: Introduce a container_parser operator for container/k8s logs parsing