
Cet article est la suite directe du précédent: Observabilité d’un cluster Kubernetes avec OpenTelemetry que j’ai séparé en deux pour le rendre plus digeste.
Les sujets traités (stanza et OTTL) sont indépendants du premier article, mais leur intérêt est directement lié à l’imperfection du parsing effectué par le File Log Receiver présenté en Partie 1 comme solution générique pour parser les logs de tous les containers du cluster Kubernetes. Dans un monde idéal, l’application source supporte nativement OpenTelemetry (il y a plein de manières différentes de rendre cela possible mais toutes supposent une intervention des développeurs de l’application). Actuellement, OpenTelemetry n’est pas encore suffisamment répandu au niveau des applications et c’est là que la flexibilité du collecteur peut élégamment compenser le manque d’intégration d’OpenTelemetry dans l’application source.
Cas d’usage présenté
Les stanza operators sont une partie fondamentale d’OpenTelemetry Collector: on les utilise souvent sans le savoir car ils sont utilisés par plusieurs composants de base. Ils sont rendus disponibles au niveau de la configuration elle-même dans certains blocs de manière générique, et dans d’autres en fonction du type de composant configuré.
OTTL quant à lui est plus général: il permet d’exprimer des instructions (avec logique conditionnelle) et est supporté dans davantage de blocs de configuration que stanza. La frontière entre les deux n’est pas toujours très intelligible dans la documentation d’OpenTelemetry. Quand on parle de fonction, il s’agit normalement de OTTL. Quand on parle d’opérateur, il s’agit plutôt de stanza.
OTTL est typiquement utilisé avec un bloc transform tel un middleware d’un
pipeline (dont l’entrée est un receiver, et la sortie un exporter): le principe
est de router les logs dans des pipelines de traitements indépendants en
fonction de l’application source, afin d’effectuer des transformations sur ces
logs, tel qu’extraire des attributs en parsant le message. Le même mécanisme est
possible pour les autres types de ressources que sont les traces (distribuées)
et les métriques mais dans cet article je ne m’intéresse qu’aux logs.
Stanza est plus restreint car c’est davantage un point d’extension de certains
composants, notamment certains receivers, eux-mêmes bâtis sur stanza, comme File
Log Receiver qui supporte l’opérateur recombine (parmi d’autres).
Tout ce qu’on peut faire dans le bloc transform est intéressant car on peut appliquer une configuration « centrale » dans un seul fichier de configuration qu’on peut enrichir pour tout ou partie des applications de notre cluster en fonction de leur importance et du temps qu’on est prêt à accorder. Quand un traitement n’est possible qu’au niveau du receiver, en revanche, on est obligé de modifier la configuration du collecteur source (celui qui parse les fichiers par exemple).
Dans la suite de cert article, on modifiera la configuration de notre troisième
collecteur (celui avec un déploiement classique, sans helm chart, présenté en
Partie 1)
lorsqu’il s’agit d’appliquer un bloc transform. Comme tous nos logs passent
par lui, cela simplifiera la maintenance. Et on modifiera la configuration du
premier collecteur (celui déployé via le helm chart « opentelemetry-collector »
en mode daemonset, présenté en
Partie 1)
lorsqu’il s’agit de faire des traitements spécifiques depuis File Log Receiver,
notamment pour supporter les logs multi lignes avec l’opérateur recombine.
Premiers conseils
Comme cette approche se fait application par application, la première chose à faire pour se simplifier la tâche est de vérifier si l’application écrit des logs dans la console en JSON, qui sera plus facile à exploiter depuis notre collecteur. Certaines applications écrivent par défaut en JSON, c’est le cas d’ArgoCD, 1Password Connect, Gotenberg (utilisé par Paperless) par exemple.
Certaines applications écrivent par défaut des messages non structurés pour
faciliter la lecture, mais peuvent être configurées pour formater leurs logs
en JSON. C’est le cas de beaucoup d’applications en Go car elles s’appuient
souvent sur le même package slog. Mais ce n’est
pas restreint à Go, Immich le propose aussi sans être en
Go (une simple recherche « immich log format » permet de tomber sur la
bonne documentation et le paramètre IMMICH_LOG_FORMAT=json).
Le format JSON évite d’avoir la problématique du multi-lignes.
Séparation des traitements en pipelines de transformation distincts
La logique étant spécifique à chaque application, il faut commencer par savoir
comment séparer nos logs en différents pipelines dans OpenTelemetry Collector.
Cela se fait avec le composant routing dans le bloc connectors et le
composant transform
dans le bloc processors.
Le rôle du composant routing est d’évaluer les conditions à remplir pour
choisir tel ou tel pipeline (avec un pipeline par défaut si les conditions
définies ne sont pas remplies). Dans notre cas, une condition classique est
d’évaluer l’attribut « container.image.name » pour identifier l’application
source et router vers un pipeline précis.
Le pipeline est ce qui décrit la source, la destination, et les traitements
(processors). On en a déjà un pour les logs, et ce qu’on veut est qu’il devienne
le pipeline par défaut, en plus de pipelines plus précis par applications. Si on
a un pipeline spécifique à une application, il contiendra un processor qui gère
les transformations souhaitées.
Voici un schéma pour mieux comprendre la structure de cette configuration:
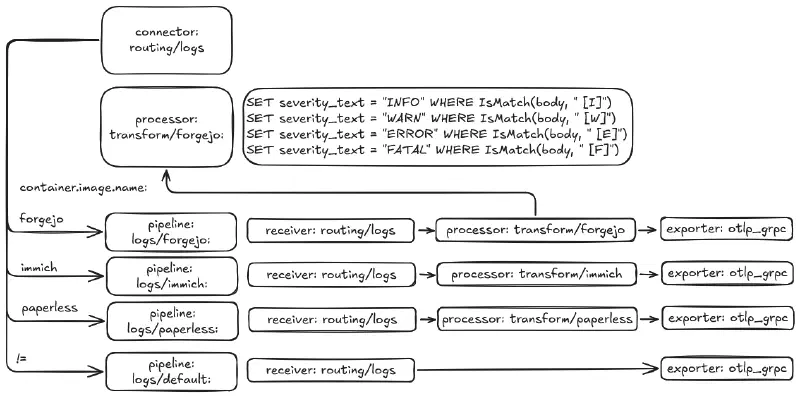
Voici ce que ça donne dans le fichier de configuration d’OpenTelemetry Collector de manière simplifiée (contenu partiel pour la lisibilité):
connectors:
# See https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/connector/routingconnector/README.md
routing/logs:
default_pipelines: [logs/default]
table:
- context: log
condition:
resource.attributes["container.image.name"] ==
"codeberg.org/forgejo/forgejo" and log.severity_text == ""
pipelines: [logs/forgejo]
- context: log
condition:
resource.attributes["container.image.name"] ==
"ghcr.io/immich-app/immich-server" and log.severity_text == ""
pipelines: [logs/immich]
- context: log
condition:
resource.attributes["container.image.name"] ==
"ghcr.io/paperless-ngx/paperless-ngx" and log.severity_text == ""
pipelines: [logs/paperless]
processors:
transform/forgejo:
error_mode: ignore
log_statements:
- context: log
statements:
- set(severity_text, "INFO") where IsMatch(log.body, " \\[I] ")
- set(severity_text, "WARN") where IsMatch(log.body, " \\[W] ")
- set(severity_text, "ERROR") where IsMatch(log.body, " \\[E] ")
- set(severity_text, "FATAL") where IsMatch(log.body, " \\[F] ")
transform/immich:
error_mode: ignore
log_statements:
- context: log
statements:
- set(log.body, ParseJSON(log.body))
- set(severity_text, "INFO") where log.body["level"] == "log"
- set(severity_text, "WARN") where log.body["level"] == "warn"
- set(severity_text, "ERROR") where log.body["level"] == "error"
transform/paperless:
error_mode: ignore
log_statements:
- context: log
statements:
- set(severity_text, "INFO") where IsMatch(log.body, " \\[INFO] ")
- set(severity_text, "WARN") where IsMatch(log.body, " \\[WARNING] ")
- set(severity_text, "ERROR") where IsMatch(log.body, " \\[ERROR] ")
exporters:
otlp_grpc:
endpoint: "http://signoz-otel-collector.signoz:4317"
# [...]
service:
extensions: # [...]
pipelines:
traces: # [...]
metrics: # [...]
logs/in:
receivers: [otlp]
processors: [memory_limiter]
exporters: [routing/logs]
logs/default:
receivers: [routing/logs]
exporters: [otlp_grpc]
logs/forgejo:
receivers: [routing/logs]
processors: [transform/forgejo]
exporters: [otlp_grpc]
logs/immich:
receivers: [routing/logs]
processors: [transform/immich]
exporters: [otlp_grpc]
logs/paperless:
receivers: [routing/logs]
processors: [transform/paperless]
exporters: [otlp_grpc]
Au fur et à mesure qu’on traite chaque application, on s’apercevra que certaines transformations peuvent être réutilisées entre plusieurs application. Par exemple des applications .NET qui utilisent le logger NLog pourront utiliser le même bloc de transformation, pareil pour des applications Go avec des logs console formatés en JSON. Dans ce cas, on pourra nommer le bloc « transform/go-json », « transform/nlog », etc. et le réutiliser dans plusieurs pipelines.
Extraire la sévérité des logs
La logique est déjà présentée dans l’exemple précédent. Il s’agit d’utiliser la
fonction set
sur le champ
« severity_text »
avec les conditions adéquates en fonction du format des logs de l’application.
Pour du texte non structuré, on utilisera typiquement la
fonction IsMatch
qui évalue une expression régulière. Attention à l’échappement de certains
caractères spéciaux: pour le texte « [I] », on doit l’échapper ainsi: « \[I] »
(on échappe avec « \ » le caractère « [ » qui a un sens particulier au sein
d’une expression régulière, et il faut échapper notre propre échappement, d’où
« \[ » au final).
Si le format des logs est structuré en JSON, on peut utiliser la
fonction ParseJSON:
transform/immich:
error_mode: ignore
log_statements:
- context: log
statements:
- set(log.body, ParseJSON(log.body)) # <--- Important
- set(severity_text, "INFO") where log.body["level"] == "log"
- set(severity_text, "WARN") where log.body["level"] == "warn"
- set(severity_text, "ERROR") where log.body["level"] == "error"
Pour être (à peu près) certain de ne traiter que des logs formatés en JSON, on
peut ajouter une condition avec la
fonction HasPrefix
dans le routage pour n’appliquer cette logique que si le log commence par {"
(en supposant du JSON sur une seule ligne sans espaces ou indentation):
routing/logs:
default_pipelines: [logs/default]
table:
- context: log
condition:
resource.attributes["container.image.name"] ==
"ghcr.io/immich-app/immich-server" and IsString(log.body) and
HasPrefix(log.body, "{\"")
pipelines: [logs/immich]
Pour l’application Gotenberg (utilisée par Paperless), le JSON contient déjà la
bonne valeur, on veut juste l’extraire en convertissant la casse de minuscules
vers majuscules avec
ToUpperCase,
donc on peut faire ainsi:
transform/gotenberg:
error_mode: ignore
log_statements:
- context: log
statements:
- set(log.body, ParseJSON(log.body))
- set(severity_text, ToUpperCase(log.body["level"])) where
log.body["level"] != nil
Noter les quelques conditions de contrôle qui sont importantes pour éviter que le collecteur ne génère de nombreuses erreurs si le log n’a pas le contenu supposé pour par ces traitements. Cela ne cassera pas le collecteur mais les traitements ne seront pas appliqués correctement et beaucoup de bruits sera généré dans ses logs (et impactera probablement ses performances).
Pour Forgejo, on peut aussi utiliser
Substring
pour retirer le timestamp du message et améliorer sa lisibilité dans le backend
final:
transform/gotenberg:
error_mode: ignore
log_statements:
- context: log
statements:
# Example: 2026/01/30 19:51:48 ...eb/routing/logger.go:102:func1() [I] router: completed GET[...]
- set(log.body, Substring(log.body, 20, Len(log.body) - 20)) where
IsMatch(log.body, "^\\d{4}/")
Ce ne sont que quelques exemples qui montrent la flexibilité fournie par le collecteur.
Au final, la transformation des logs Forgejo est semblable à:
Log initial:
{
"body": "2026/01/30 19:51:48 ...eb/routing/logger.go:102:func1() [I] router: completed GET /v2/soho/livebox-exporter/tags/list?n=1000 for 10.42.0.1:0, 401 Unauthorized in 2.7ms @ packages/api.go:45(packages.ContainerRoutes.reqPackageAccess)",
"date": "2026/01/30 19:51:48.682426472Z",
"timestamp": "2026/01/30 19:51:48.682426472Z",
"resources": {
"container.image.name": "codeberg.org/forgejo/forgejo",
// [...]
},
"severity_text": "",
// [...]
}
Log final:
{
"body": "...eb/routing/logger.go:102:func1() [I] router: completed GET /v2/soho/livebox-exporter/tags/list?n=1000 for 10.42.0.1:0, 401 Unauthorized in 2.7ms @ packages/api.go:45(packages.ContainerRoutes.reqPackageAccess)",
"date": "2026/01/30 19:51:48.682426472Z",
"timestamp": "2026/01/30 19:51:48.682426472Z",
"resources": {
"container.image.name": "codeberg.org/forgejo/forgejo",
// [...]
},
"severity_text": "INFO",
// [...]
}
Dans le backend, on pourra donc facilement filtrer les logs en fonction de leur sévérité.
Extraire des champs formatés dans un message syslog
Je digresse légèrement par rapport au sujet Kubernetes: supposons qu’on ait ajouté un Syslog Receiver dans notre collecteur. Ce receiver parse les quelques champs communs à tout message syslog et le message peut contenir un format plus spécifique.
Dans mon cas, je route les messages syslog de mon pare-feu pfSense vers OpenTelemetry Collector pour les retrouver dans mon backend. Les logs du pare-feu sont filtrables grâce au champ “appname = ‘filterlog’”, mais leur format est assez indigeste:
{
"body": "<134>Jan 30 15:26:45 filterlog[59421]: 358,,,1696100326,REDACTED,match,block,in,4,0x0,,128,13281,0,DF,6,tcp,52,REDACTED,REDACTED,60061,1234,0,S,3020203055,,65535,,mss;nop;wscale;nop;nop;sackOK",
"date": "2026-01-30T13:26:45Z",
"id": "0kHDaA0vGLo2rxBjUE5RCi8YzRm",
"timestamp": "2026-01-30T13:26:45Z",
"attributes": {
"facility": 16,
"priority": 134,
"appname": "filterlog",
"facility_text": "local0",
"message": "358,,,1696100326,REDACTED,match,block,in,4,0x0,,128,13281,0,DF,6,tcp,REDACTED,REDACTED,60061,1234,0,S,3020203055,,65535,,mss;nop;wscale;nop;nop;sackOK", // <--- We want to extract some attributes from this message
"proc_id": "59421"
},
"severity_text": "info"
}
Les information clé sont dans le message suivant (“REDACTED” contenait des adresses IP ou des informations de ma configuration réseau):
358,,,1696100326,REDACTED,match,block,in,4,0x0,,128,13281,0,DF,6,tcp,REDACTED,REDACTED,60061,1234,0,S,3020203055,,65535,,mss;nop;wscale;nop;nop;sackOK
Ce type de log peut être transformé avec les fonctions
ExtractPatterns
et
merge_maps:
transform/pfsense-filterlog:
error_mode: ignore
log_statements:
- context: log
statements:
# See https://docs.netgate.com/pfsense/en/latest/monitoring/logs/raw-filter-format.html
- merge_maps(log.cache, ExtractPatterns(log.body,
"<\\d+>\\w+\\s\\d{1,2}\\s\\d{1,2}:\\d{1,2}:\\d{1,2}\\s(\\w+?)\\[\\d+]:\\s\\d+,\\d*?,.*?,\\d+,(?P<net_interface>[^,]+),(?P<firewall_reason>[^,]+),(?P<firewall_action>[^,]+),(?P<firewall_direction>[^,]+),\\d,[^,]*,[^,]*,[^,]*,[^,]*,[^,]*,[^,]*,[^,]*,(?P<firewall_protocol>[^,]+),\\d*,(?P<firewall_src_addr>[^,]+),(?P<firewall_dst_addr>[^,]+)"),
"upsert")
- set(log.severity_text, "WARN") where log.cache["firewall_action"] !=
nil and log.cache["firewall_action"] != "pass"
- set(log.attributes["net_interface"], log.cache["net_interface"])
- set(log.attributes["firewall_reason"], log.cache["firewall_reason"])
- set(log.attributes["firewall_action"], log.cache["firewall_action"])
- set(log.attributes["firewall_direction"],
log.cache["firewall_direction"])
- set(log.attributes["firewall_protocol"],
log.cache["firewall_protocol"])
- set(log.attributes["firewall_src_addr"],
log.cache["firewall_src_addr"])
- set(log.attributes["firewall_dst_addr"],
log.cache["firewall_dst_addr"])
Le résultat transformé est le suivant:
{
"body": "<134>Jan 30 15:26:45 filterlog[59421]: 358,,,1696100326,REDACTED,match,block,in,4,0x0,,128,13281,0,DF,6,tcp,52,REDACTED,REDACTED,60061,1234,0,S,3020203055,,65535,,mss;nop;wscale;nop;nop;sackOK",
"date": "2026-01-30T13:26:45Z",
"id": "0kHDaA0vGLo2rxBjUE5RCi8YzRm",
"timestamp": "2026-01-30T13:26:45Z",
"attributes": {
"facility": 16,
"priority": 134,
"appname": "filterlog",
"facility_text": "local0",
"message": "358,,,1696100326,REDACTED,match,block,in,4,0x0,,128,13281,0,DF,6,tcp,REDACTED,REDACTED,60061,1234,0,S,3020203055,,65535,,mss;nop;wscale;nop;nop;sackOK",
"proc_id": "59421",
"firewall_action": "block",
"firewall_direction": "in",
"firewall_dst_addr": "REDACTED",
"firewall_protocol": "tcp",
"firewall_reason": "match",
"firewall_src_addr": "REDACTED",
"net_interface": "REDACTED"
},
"severity_text": "WARN"
}
Dans le backend, on peut ainsi obtenir une vue facilement exploitable:
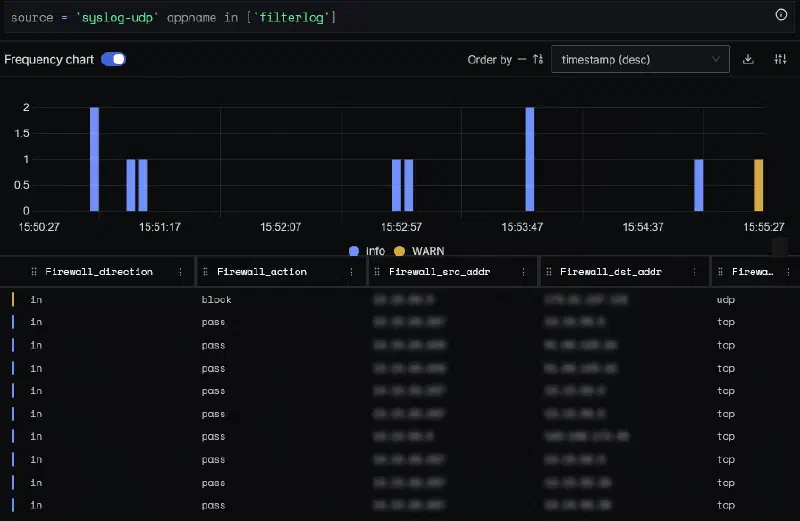
Recombiner des logs multi-lignes
Cette partie est plus difficile.
Sans configuration particulière, le File Log Receiver parse chaque ligne comme une ligne de log individuelle. Cela pose problème sur certaines applications, et typiquement sur les logs contenant une stacktrace d’erreur détaillée.
Il n’est malheureusement pas possible de compenser cela en aval depuis notre
collecteur central car
l’opérateur recombine
qu’on va utiliser n’est supporté qu’au niveau du receiver
(File Log Receiver).
Il faudra donc modifier la configuration du premier collecteur déployé via un
helm chart “opentelemetry-collector”, grâce à un fichier “values.yaml” qui
embarque la configuration du collecteur.
Regardons déjà à quoi ressemble la configuration de ce collecteur, générée par le helm chart (en supposant qu’on a installé le helm chart dans un namespace “otelcol-k8s”):
$ kubectl get cm -n otelcol-k8s
NAME DATA
kube-root-ca.crt 1
otel-collector-k8s-daemonset-opentelemetry-collector-agent 1
otel-collector-k8s-deployment-opentelemetry-collector 1
Celui qui nous intéresse est celui en mode daemonset, donc: “otel-collector-k8s-daemonset-opentelemetry-collector-agent”.
Son contenu ressemble à ceci (partiel et légèrement reformaté pour une meilleure lisibilité):
kubectl get cm otel-collector-k8s-daemonset-opentelemetry-collector-agent -n otelcol-k8s -o yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: otel-collector-k8s-daemonset-opentelemetry-collector-agent
namespace: otelcol-k8s
data:
relay: |
receivers:
filelog:
exclude:
# [...]
include:
- /var/log/pods/*/*/*.log
include_file_name: false
include_file_path: true
max_concurrent_files: 10
operators:
- id: container-parser
max_log_size: 102400
type: container
poll_interval: 3s
retry_on_failure:
enabled: true
start_at: end
service:
extensions: [ health_check ]
pipelines:
logs:
exporters: [ otlp_grpc ]
processors: [ k8sattributes, memory_limiter, batch ]
receivers: [ otlp, filelog ]
Comme ce ConfigMap est généré par le helm chart et qu’on ne peut que configurer
le helm chart, on pourra laisser le “filelog” existant et en ajouter d’autres
plus spécifiques. Dans le “filelog” initial, on ajouter les fichiers supportés
par une instance spécifique dans le bloc exclude (pour ne pas traiter les
mêmes logs par plusieurs instances de File Log Receiver).
Je ne détaillerai pas comment mettre à jour le ConfigMap généré par le helm
chart, cela se fait en appliquant une nouvelle configuration avec la commande
helm upgrade <release-name> open-telemetry/opentelemetry-collector -f values.yaml.
Et ce qui est présentré dans cet article peut être appliqué à d’autres types de
déploiements du collecteur, sans helm chart.
La documentation de l’opérateur est très détaillée avec divers exemples pour comprendre différents scénarios d’utilisation.
Dans mon cas, j’ai plusieurs applications .NET qui utilisent la librairie NLog.
Les logs générés ont une forme telle que “[Info] LoggerName: message”. En cas
d’exception, celle-ci est incluse dans un log multi lignes. Le marqueur pour
recombine est de déterminer si la ligne commence par une sévérité (Info,
Error, etc.). Si oui, c’est la première ligne d’un log. Sinon, c’est une ligne à
merger avec le précédent log.
Voici un exemple fonctionnel pour mon usage:
filelog/nlog:
# More specific parsing based on NLog logger output
poll_interval: 3s
max_concurrent_files: 10
include_file_name: false
include_file_path: true
retry_on_failure:
enabled: true
start_at: end
include:
# Any entry here should be added in exclude bloc of base filelog receiver.
- /var/log/pods/<namespace>_<pod_name>-*/<container_name>/*.log
operators:
# See https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/pkg/stanza/docs/operators/container.md
- id: container-parser
max_log_size: 102400
type: container
- id: recombine
type: recombine
combine_field: body
is_first_entry:
'body matches "^\\[(Fatal|Error|Warn|Info|Debug|Trace)] (\\w+): "'
Ce nouveau filelog/nlog est à ajouter (en sus de l’existant filelog). Et il
faut ajouter le contenu de include de notre nouvel élément dans exclude du
premier pour éviter de traiter ces logs en double.
Enfin dans le bloc pipelines, on ajoute notre nouveau receiver ainsi:
service:
pipelines:
# [...]
logs:
exporters: [otlp_grpc]
receivers: [otlp, filelog, filelog/nlog] # <--- filelog/nlog added here
Avec cette configuration, il suffit d’adapter le chemin des fichiers dont on sait qu’ils ont pour source un logger NLog pour que les logs multi lignes soient correctement traités.
Pour K8up (gestionnaire de backups de volumes Kubernetes vers une API S3, que
j’ai présenté dans
mon article précédent),
chaque log commence par un timestamp tel que “2026-01-30T13:52:41Z […]”, on
peut donc par exemple utiliser
is_first_entry: 'body matches "^\\d{4}-\\d{2}-\\d{2}T"'.
Je pense avoir couvert une bonne partie des cas les plus classiques. Pour aller plus loin, on pourra se référer à la liste des opérateurs stanza et à celle des fonctions OTTL pour se faire une idée des possibilités.